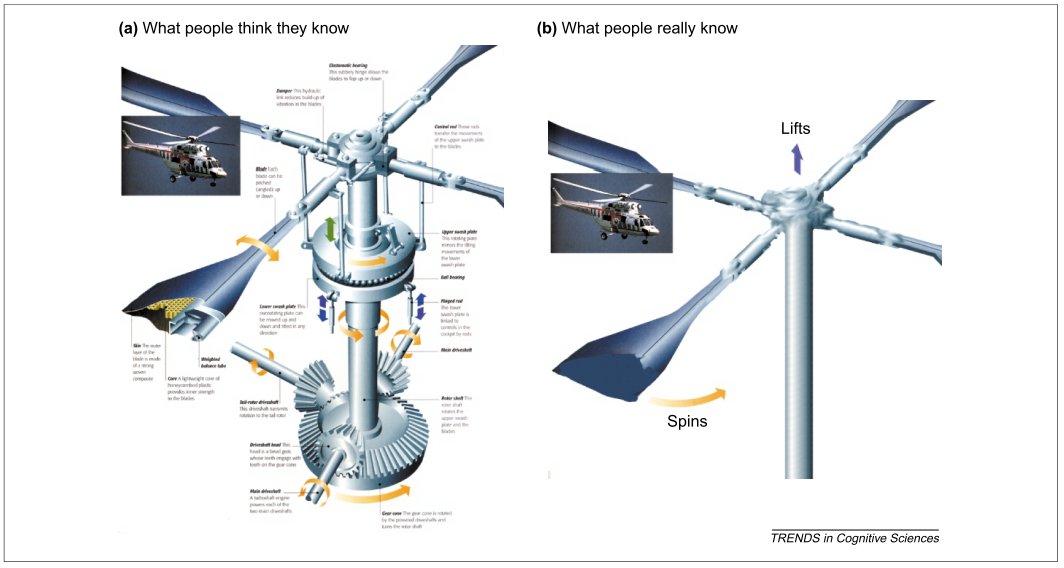
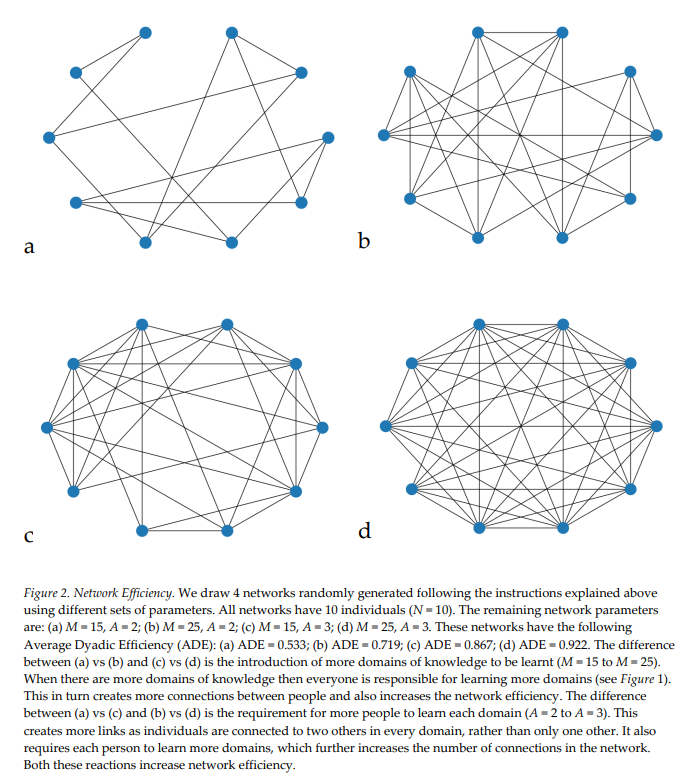
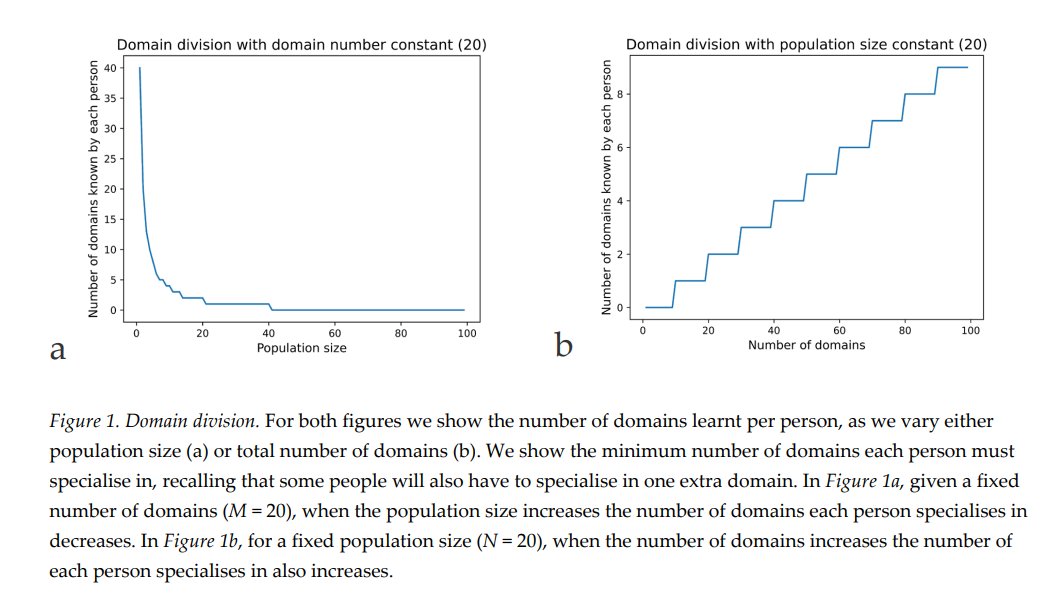
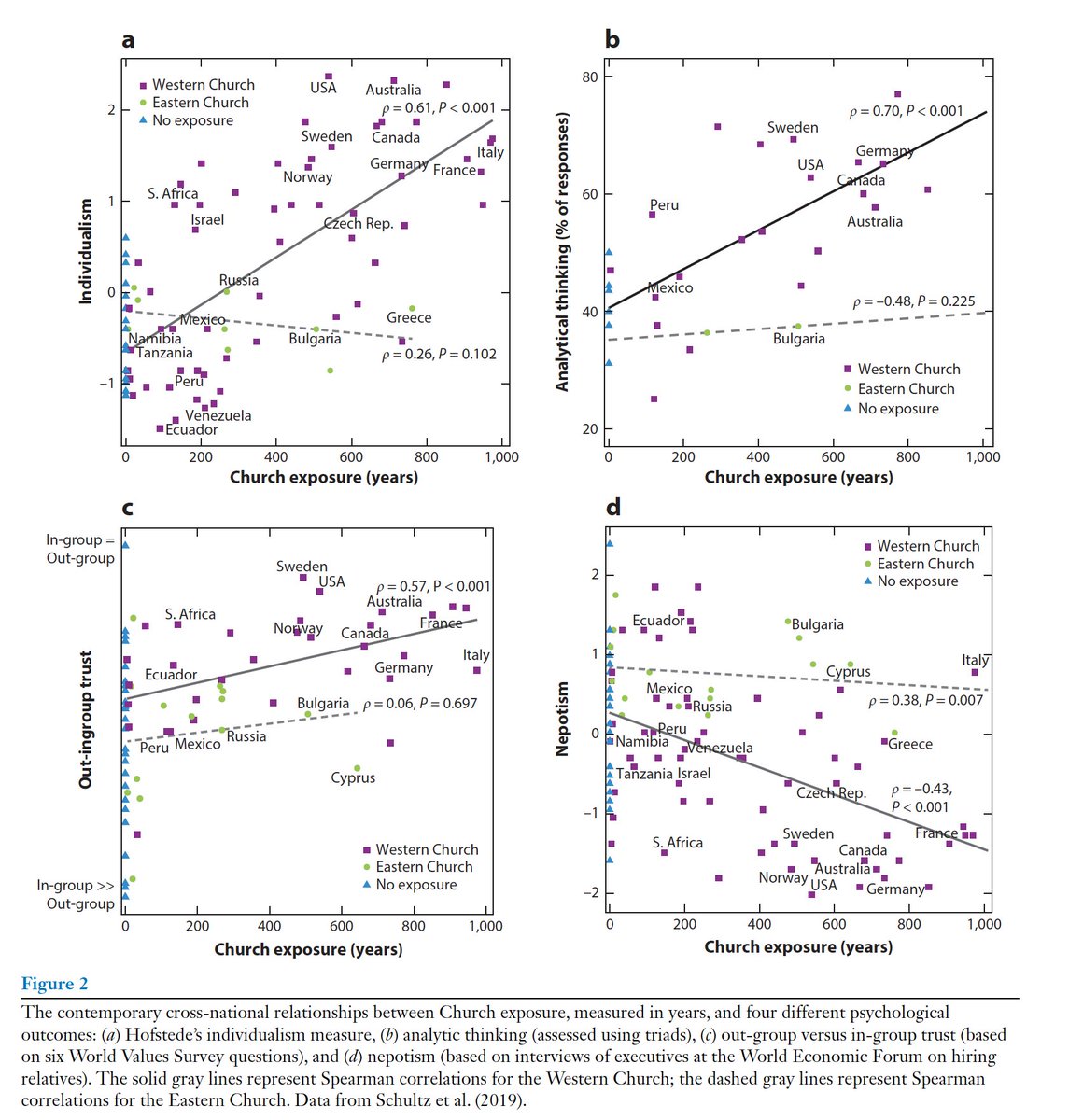
Here’s the take home: Studying hardware won’t help you understand the capabilities of pivot tables in Excel nor Code Interpreter in ChatGPT.
Your head is filled with entire analogies, metaphors, epistemologies, and tools that you once learned and now effortlessly use for thinking. It’s how you cook, how you count, and why you think invisible germs are a good explanation for disease. But invisible spirits are not.
Studying our genes and neural hardware won’t help you understand human intelligence. Our cultural software endows us with *new* cognitive capabilities.
How does this software get written? How do we become more brilliant, creative, and improve our education systems?
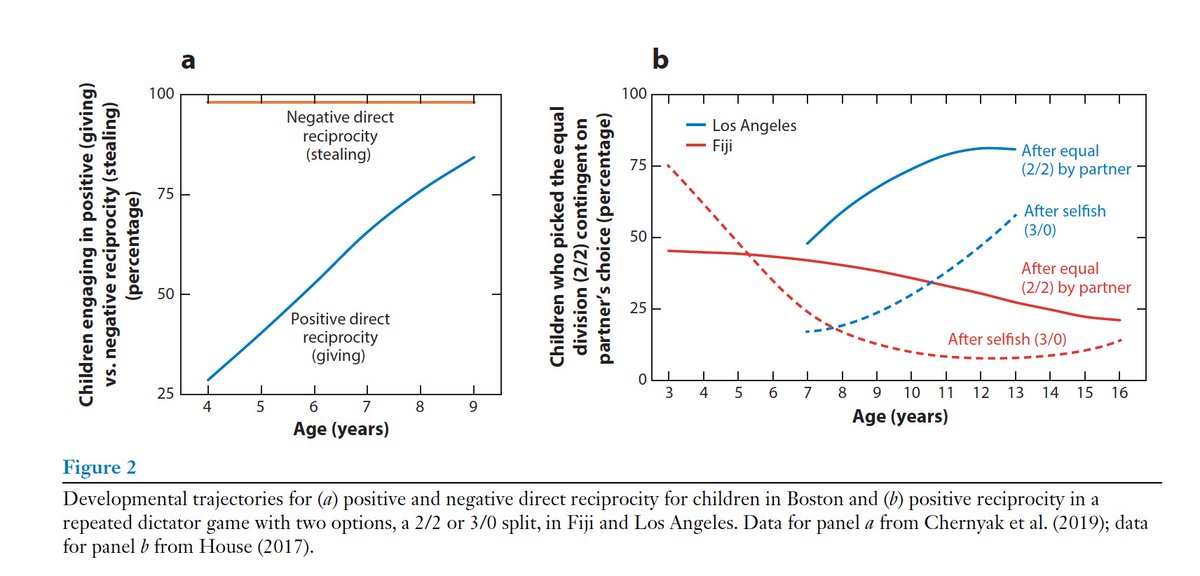
Consider how we count. We went from counting 1, 2, 3, many, as some small-scale societies still count, to a full-blown number system. Numbers likely emerged as an innovation for more efficiently tracking cattle and crops – you need to know who owes you what!
This new cognitive capability used a metaphor – fingers. But there’s nothing unique about fingers & 10 is awkward (16 would be better). Cultures have counted on body parts from base 6 to 27. But to count beyond body parts, we needed a different metaphor. Something like stones.
‘Calculus’ comes from ‘pebble’ (think calcium or limestone), and was used for addition and subtraction. Stones let you think about addition or subtraction beyond how creative you can get with body parts. There are some stones, and you can throw down more or snatch some away.
Stones are great for natural numbers: 1, 2, 3, 4, 5, etc. But stones don’t make zero obvious. What does zero pebbles look like? It looks a lot like zero of everything else – it’s nothing – and ‘nothing’ is hard to imagine. Zero came a lot later. What about negatives?
The number line as a metaphor helped make zero more concrete and easily transmissible even to children. Number lines work by mapping numbers not to objects but to movement and position, but they also revealed the negative numbers, which are not otherwise intuitive!
“Negative numbers darken the very whole doctrines of the equations and make dark of the things which are in their nature excessively obvious and simple” as Francis Maseres complained in the 18th century.
Nothing about numbers is intuitive to our ape brains. But these metaphors, mental models, and cultural innovations – cultural software – literally changed our minds and gave us new capacities. They’re like software upgrades.
These kids have a Soroban abacus in their heads allowing them to swiftly add large sums: 3267 + 9853 + 6531 + 7991 + 2641 in seconds. It’s a brand new cognitive capability. New cultural software. Video here: https://twitter.com/mmuthukrishna/status/1684576156803289091?s=20
Some innovations are more general than others. For example, thanks to the invention of writing, I can convey information through straight and squiggly lines on a page. I’m doing it right now and I’m literally changing your brain.
Another lesson: Mental tools can go out of date. Mental math became less useful. My middle school teacher, warned us about not being able to +, -, x, / without a calculator (because we wouldn’t be carrying calculators in our pocket). He didn’t foresee the arrival of the iPhone.
Much of what we assume are human capabilities are actually cultural software, invented and transmitted. This can be hard to see because we all live in a bubble. Academics in Ivory Towers, coastal elites, rural small towns – all part of a big bubble.
Almost everyone you’ll ever meet went to school; can all read, write, & count; and consumes some form of television and online media.
Breaking out of this big bubble requires going back in time or to far-flung places.
If our cultural software is what makes us smart, it means that we can be deliberate in how it gets written. We can seek out new mental models, intellectually arbitrage our way to creativity & discovery, and revitalize our education systems.
If you liked this post and want to learn more about how cultural evolution can be applied to our lives, companies, and societies, please pre-order A Theory of Everyone: https://linktr.ee/theoryofeveryone. Pre-orders really help with the success of the book and Amazon pre-orders guarantee the lowest price. Thank you!
Muthukrishna, M. (2023). [BOOK] A Theory of Everyone: Who we are, how we got here, and where we’re going. MIT Press (US & Canada) / Basic Books (UK and Commonwealth) [Amazon and Local Bookstores]
Schnell, E., Schimmelpfennig, R., & Muthukrishna, M. (2023). The Size of the Stag Determines the Level of Cooperation. bioRxiv
Muthukrishna, M., Henrich, J. & Slingerland, E. (2021). Psychology as a Historical Science. Annual Review ofPsychology, 72, 717-49. [Download] [Publisher] [Twitter]
Henrich, J. & Muthukrishna, M. (2021). The Origins and Psychology of Human Cooperation. Annual Review ofPsychology, 72, 207-40. [Download] [Publisher] [Twitter]
The title of my talk was “The Evolution of Comity: Ultimate Constraints on the Scale of Cooperation.” Key publications relevant to this discussion are:
The research is related to my book, and a grant focused on expanding our comprehension of the foundational processes facilitating cooperation, with the goal of enhancing social harmony and unity. I am grateful to the faculty, students and staff at Mohammed VI Polytechnic University for the invitation and their hospitality.
Here’s the take home: diversity empowers innovation through recombination but also by definition divides us. We call this the paradox of diversity. A principled way to resolve this tension is by considering cultural evolvability.
We discuss implications for entrepreneurship, polarization & a nuanced take on diversity. This framework can also guide researchers and practitioners in how to reap the benefits of diversity by reducing costs.
Let’s start with innovation: A folk understanding of innovation is that it’s driven by a talented few – the giants upon whose shoulders we stand. But that view is inconsistent with theoretical and empirical work in cultural evolution.
Instead, innovations emerge as ideas flow through our social networks, requiring a specific innovator no more than your thoughts require a specific neuron. See: Innovation in the Collective Brain
People are often unaware of how little they actually deeply understand about the world – what’s referred to as the “knowledge illusion” or “illusion of explanatory depth”. The Knowledge Illusion is a good pop book on the topic.
The world is not only complicated, but more complicated than our psychology allows us to believe. Innovations emerge through incremental improvements through partial causal models and large leaps through serendipity & recombination.
Three key levers that affect innovation are sociality (size & interconnectedness of a population), transmission fidelity (how well you can transmit information between people), & cultural trait diversity. Diversity has the most potential benefit and the largest challenges.
Let me say a bit about each. 1. Sociality: in general +ve relationship, because large pops had to solve the coordination problem to become large. Interconnectivity has an optimal point. Small work groups can be easily overconnected; large pops should be more connected.
2. Transmission fidelity: under selection as cultural complexity increases. Hunter-gatherers not much explicit instruction.Industrial revolution eventually led to schools to download a minimum common cultural package – reading, writing, arithmetic, algorithms for thinking.
Today we have the printing press, radio, TV, Internet, social media, and Zoom. But there’s still too much to learn. Unless you get a PhD, 21C students don’t learn mathematics developed after 1900; scientific training is longer, & major contributions are made at an older age.
We spend longer learning, delaying kids. Theres limit to pop size & transmission; how long you can delay being productive. Another path is to divide up info & labor-specialize. Get smart at 1 thing & stupid at everything else: cultural trait diversity
Different kinds of diversity & different ways to measure it. Our focus is on cultural trait diversity-beliefs, behaviors, assumptions, values, technologies, & other transmissible traits. e.g. languages, processing techniques, technical skills, family structure & occupation.
In the public discourse, diversity often refers to ancestry or physical characteristics-skin color, ethnic origin, religion, sex, gender, sexual orientation, or ability. These may correlate with cultural trait diversity, but correlation may weaken over generations.
For example, Americans with different ancestries may possess similar WEIRD psychology (part of why I have an issue with the WEIRD=White take, though that’s a separate issue). I’ll use diversity from herein, but that’s what we mean.
Diversity can be distributed in different ways: Diversity between pops culturally evolves as pops adapt to local differences, influencing future generations through historical path dependence created by past conditions or founder populations. See also: Psychology as a Historical Science
Diversity within populations evolves as information and labor are divided as discussed above.
Within-population diversity includes disciplinary differences, such as the sciences and humanities, industry specialisations, guilds, and firms. Diversity can be structured as ‘cultural clusters’ by ethnicity, class, wealth, occupation, politics, religion, or incidental geographic layout. Cultural clusters may intersect, such as in ethnic occupation specialization-lots of examples. See also: Beyond WEIRD Psychology: Measuring and Mapping Scales of Cultural and Psychological Distance
Diversity may also exist within certain individuals—multicultural individuals, ‘third culture kids’ (like Barack Obama), interdisciplinary researchers, and so on.
Diversity is therefore both the product of cultural evolution and fuel for the engine of further innovation
But without common understanding & common goals, the flow of ideas in social networks is stymied, preventing recombination, and reducing innovation. Consider communication without a common language or collaborations between scientists & humanities, or different scientists.
We formalize this paradox of diversity trade off in the paper and will be exploring solutions in future work. Check out the paper for details. We argue cultural evolvability is the right way to think about this.
Evolvability refers to not how well adapted a population is to current circumstances, but its ability to evolve to future circumstances. Variation or diversity, and the forces that create and stabilise that diversity are key factors that create evolvability.
Cultural evolvability is a balance between diversity and selection, exploring and exploiting, sampling and specialising, convergent and divergent thinking, stability and change, efficiency and flexibility.
Lots of related work on diversity and selection, explore-exploit or sampling-specialising trade-off in development, search for global solutions & avoidance of saddle points within machine learning.
As an aside, ML insights: in a sufficiently high dimensional space there are effectively no local optima, only saddle points with some dimension that allows escape. Biological & cultural systems have large dimensionality, there are no true evolutionary stable equilibria.
Next, we review the diversity literature through the lens of cultural evolvability. First we lay out 9 challenges to interpreting the literature. It’s a literature that would be benefit from theory. See also: A Problem in Theory
Diversity overlaps with challenging aspects of psychology, norms & institutions: racism, prejudice, xenophobia, sexism, discrimination, power differences, social and economic inequalities.
Love to write about at some point, here we focus on coordination challenges, which influence and are influenced by these problematic features of the world. Our goal is to review the overall patterns in the literature and make sense of these in light of cultural evolvability.
Here’s some of the mixed lit: Within countries, diversity is often approximated by birthplace diversity, professional diversity, ethnic diversity or linguistic diversity. Research looking at the relationship between diversity and economic growth suggests: positive effect of birthplace diversity, but -ve effect of ethnic and linguistic diversity. Research asking questions about immigrants in general often ignore the heterogeneity – cultural distance and education (effectively the cultural traits in your head) matter. Even more mixed in firms. Overall, educational diversity and deep level diversity seem to be positive for innovation within a firm. Mixed effects within teams – we think the paradox of diversity can disentangle.
We derive some insights:
1. Cultural evolvability means tolerance for diversity. Currently less adaptive traits may be more adaptive when the environment changes. Different environments lead to different evolvability strategies. In materially insecure societies, not following a successful “Tiger Mom” strategy—working hard to secure scarce educational opportunities and subsequent employment opportunities—has a much larger cost. But this leads to incremental over radical innovation.
2. Cultural evolvability means under-optimization & inequality. Cultural evolvability necessarily means inequality in outcomes, because not all will have the optimal strategy for the current environment.
Firms face a tradeoff: strategies that favour efficiency & strategies that favour flexibility. Consistent, strong cultures perform well in stable markets, but poorly during times of change. Under-optimizing and allowing for flexibility increases a firm’s evolvability.
Not all firms can bear the cost of under-optimising in the short term-high risk, high value approaches better suited to larger firms or larger countries. Read about Satya Nadella and Microsoft:
Compromize strategies: skunkworks, ecosystems of different firms trying different strategies (e.g. Silicon Valley), or countries composed of different states or regions trying different approaches (e.g. what Justice Brandeis described as “laboratories of democracy”).
In shared multi-agent reinforcement learning, diversity increases performance through exploration and individualized behaviors. Evolvability means many approaches will be suboptimal or even fail, but the successful approaches can be spread and benefit the group as a whole.
Indeed one of the benefits of access to multiple cultures in pluralistic, multicultural societies is the ability to create new approaches by learning, borrowing, copying from each other and other cultures. We should do more of that.
3. Cultural evolvability helps explain levels of entrepreneurship. Cultural evolvability requires doing something different. Most new businesses fail & the willingness to take a risk depends on personal and population-level costs and benefits.
A. personal cost of deviation: many deviations will result in lower payoffs than following the majority trait. If it were obvious how to do better, most of the population would already use the better strategy. Tolerating diversity in traits, thus, means tolerating failure.
Reducing cost of failure increases entrepreneurship: bankruptcy laws, social safety nets, rich parents – a child with parents in the top 1% income distribution is 10 times more likely to be an inventor than a child born below the median, controlling for measures of ability.
B. population-level benefit of deviation. In a large economy with a large customer base comes large rewards for large innovations – the few winners can win bigger. Amazon can make more money in the United States than in Australia. Here’s a great video of Bezos describing his vision back in 1997:
C. Who pays the cost and who benefits from the innovation at a population-level, a function of the scale of cooperation. Even if at an individual-level the benefits of entrepreneurship don’t outweigh costs, they may do so at a population-level.
Silicon Valley offers an example. For every Apple & Amazon, there are 1000s of start-ups that have failed – most start-ups fail & the overwhelming majority never receive funding (114) – ‘unicorns’ are called unicorns for a reason. But the few successes pay for the failures.
4. Cultural evolvability prevents polarization & cultural speciation. Harshly punishing minor deviations increases extremism. If you’re harshly punished anyway, may as well take the extreme position. If there weretolerance for diverse view points, I’d moderate my position.
Model and results also inform debates on freedom of speech, predicting large sanctions for small deviations may encourage a divided society. By corrolary tolerating multicultural diversity of opinions and cultural traits may prevent polarization.
Cultural clustering complicates everything, but I’ll let you read about that in the paper. It gets into colonialism, resource competition, and intergroup violence. 50/ To conclude, diversity has been central to the success of all life. Until around 1.2 billion years ago the source of that diversity was mutation – genetic innovation through serendipity and incremental improvement alone. Single cells reproducing by simple replication.
Sex unlocked the recombinatorial power of diversity, increasing evolvability and the speed of evolution. So too with culture, but there are many barriers to cultural traits meeting and recombining.
We live in an increasingly connected & multicultural world. Migration is a constant feature of the human story, but since the Age of Mass Migration, more people from more culturally distant societies live side by side. Their countries of origin must coordinate as never before.
So much human potential is lost through unequal access to information and adaptive cultural traits. The goal of any society or org should be to reap the benefits of diversity and minimize the costs, thereby maximizing human potential. We discuss several strategies.
Humans are a deeply cooperative species. Our greatest achievements and our worst atrocities are both cooperative acts. In a more diverse world, the challenge is greater, so too are the potential gains.
🚨New paper (& #RStats pckg) in Psych Methods: “Parsimony in Model Selection: Tools for Assessing Fit Propensity” w/ Carl Falk
Say you have 2 theories rep in 2 stats models. Which theory/model is correct? The one that best fits the data right?
Ok, but what about parsimony?
Occams razor: given 2 equally fitting models, all else being equal pick the simpler / more parsimonious, model. But how do you quantify parsimony?
Some researchers equate parsimony with degrees of freedom, but as we show you can have fewer parameters, but less parsimony.
Another way to think about it is what Kris Preacher called “fit propensity”. Some models may fit the given data better not because they represent a more correct theory, but because they would fit any data better. Even nonsensical data. It’s the opposite of parsimony.
Incidentally, the context for this research is the theory crisis and the importance of formalizing theory, even if in a statistical model. More here:
New paper: we argue that the replication crisis is rooted in more than methodological malpractice and statistical shenanigans. It’s also a result of a lack of a cumulative theoretical framework: & (nature.com/articles/s4156…)(muth.io/theory-nhb)
Back to fit propensity.
Fit propensity is often ignored in model selection. Perhaps because the answer to “how do we assess fit propensity?” has been “not easily”. In this paper, we fix that.
We offer a toolkit and 5 step process for researchers to assess parsimony of SEMs using an R package (ockhamSEM).
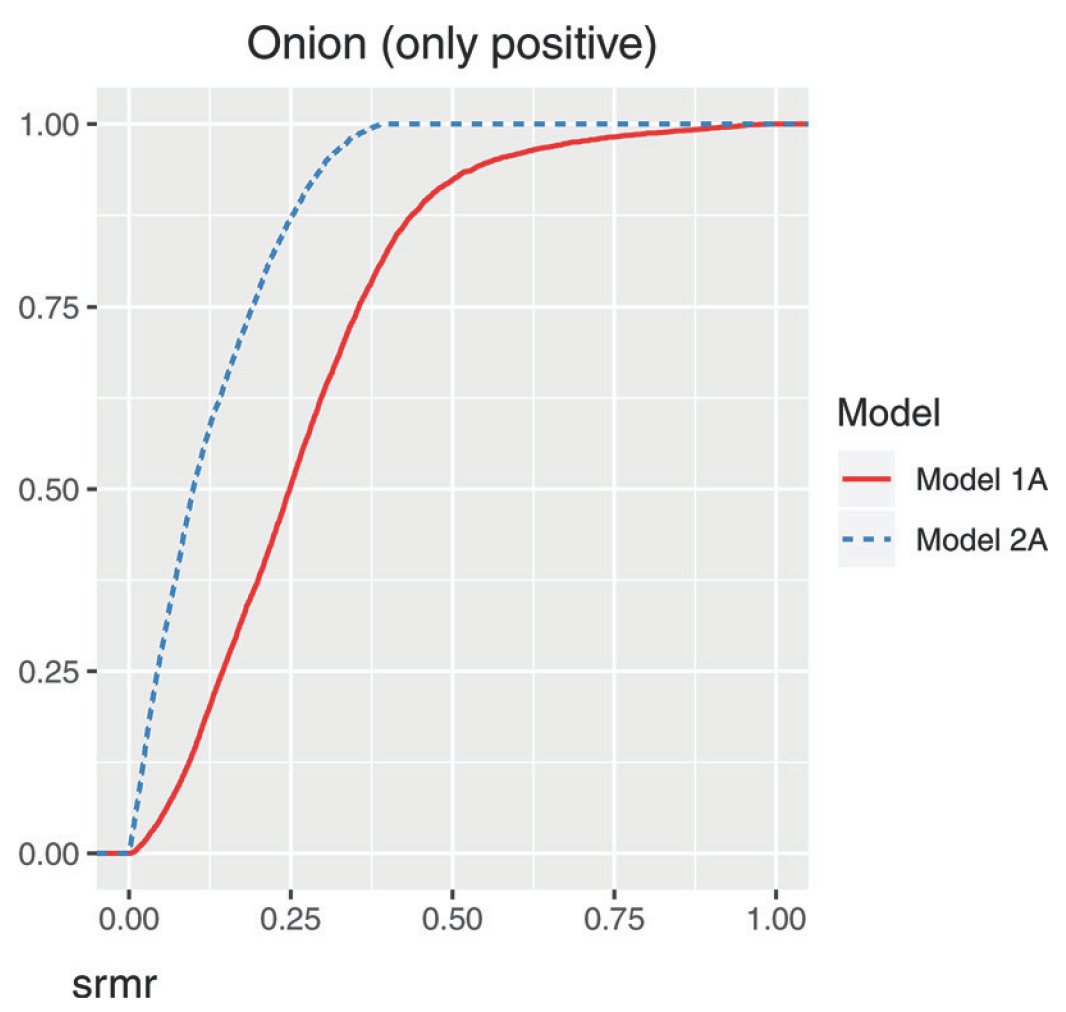
Basic idea: generate random data (or constrained random data, e.g. only positive) as covariances and see which model fits better in this universe of nonsense.
So in the opening model, using standard model selection approach, you might conclude that 2A is a better model than 1A. 2A has a lower AIC so it’s the best theory for generating the data, etc. But you’d have ignored that 2A lacks parsimony.
2A fits a wider range of data better – even nonsense.
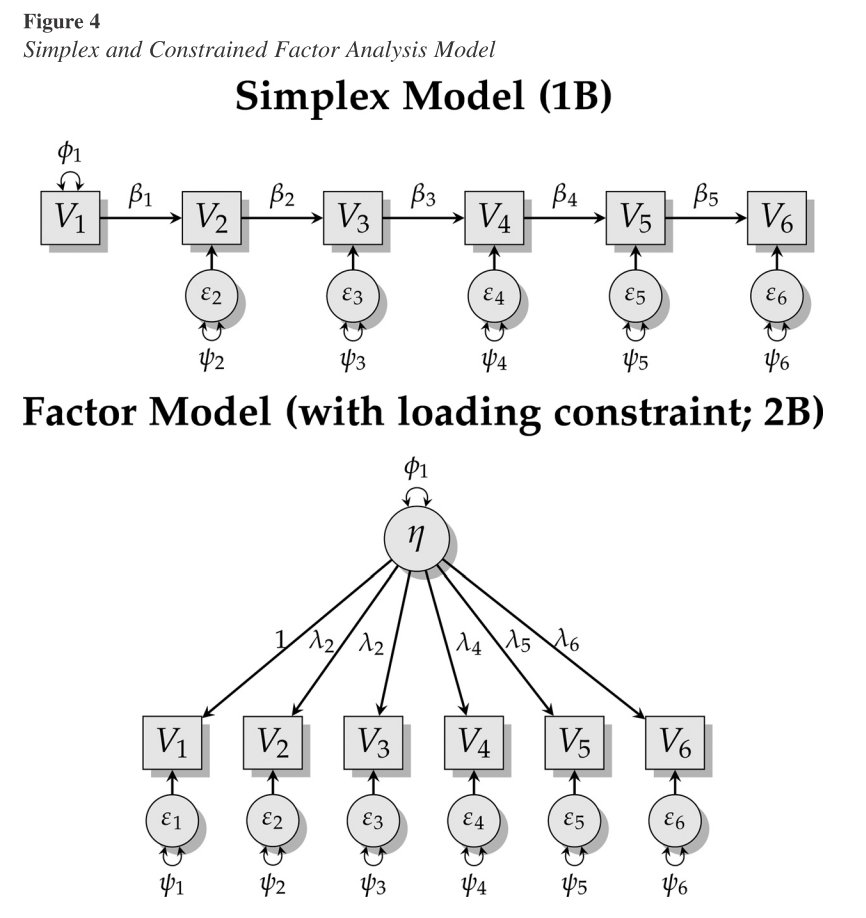
Between these models, you might think the factor model is a better fit than the simplex model, but it lacks parsimony – much more so if the data are all positive covariances!
To show some of the complexities of considering parsimony, we investigate the factor structure of the Rosenberg Self-Esteem Scale.
Spoiler: fit indices interact with fit propensity.
Some quick background: Religions bind people into communities with moral norms about what is right, good, & true. Ever notice that major world religions seem to have some broad stroke similarities like big families and being nice to neighbors? Why is that?
One hypothesis is that having those helped those religions grow in the competition with other religions. Not all religions in history share these features. The Shakers, for example, an offshoot of the Quakers, practiced celibacy not just for a priestly class, but for all.
The Shakers are no longer with us.
But religions also have plenty of differences, not only in explicitly religious beliefs, but in broader cultural values that affect national culture. Jesuits and Mainline Protestants, for example, historically increased levels of education. And Protestant values may help explain America’s traditionalism, individualism, and moralization of work. Religions are also shaped by national culture, taking on regional forms. Here’s a buff, Korean Jesus:
Some have also argued that “religion” is mostly a label or an identity, swamped by national culture – think nominal Christians. Or religion may just predict overtly religious beliefs, rituals, and moral attitudes.
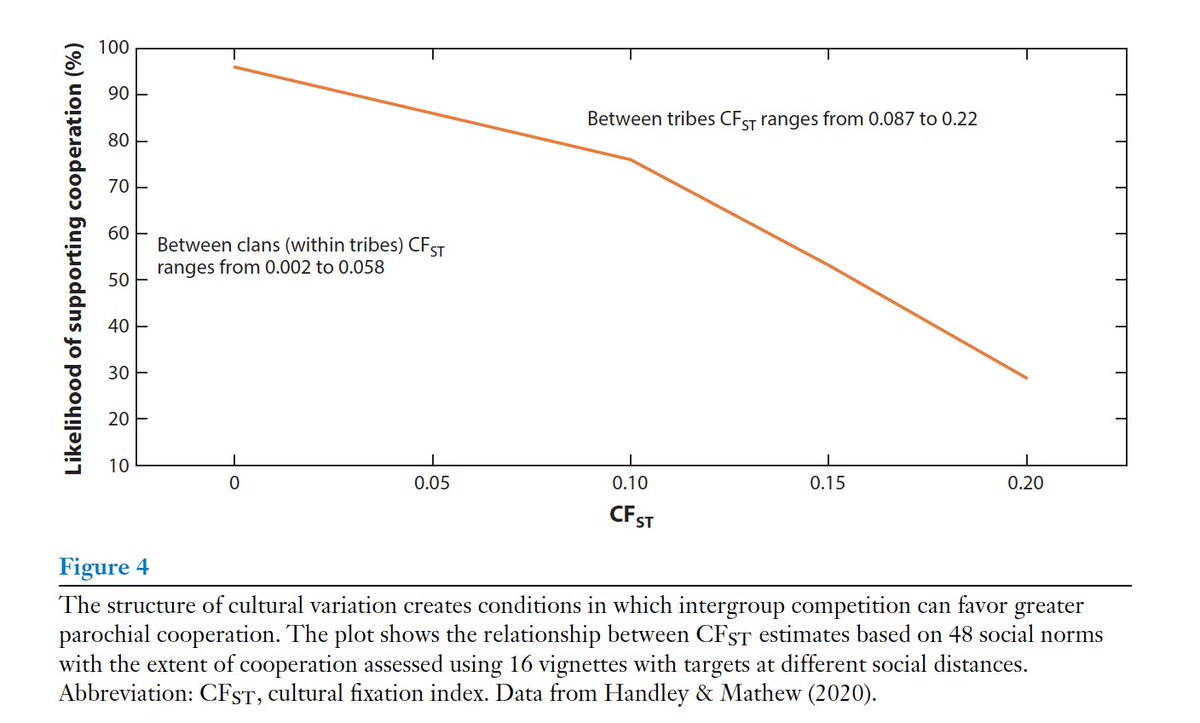
For the cultural-group selection theory to work, major world religions should be “super-ethnic” identities, binding people beyond their ethnicity or national borders. That is, those who share a religion living in different countries should be more similar to those who don’t share the religion.
Using a new method for measuring cultural distance called the Cultural Fixation Index (CFst; read more about it here: https://www.michael.muthukrishna.com/beyond-weird-psychology-measuring-and-mapping-scales-of-cultural-and-psychological-distance/), we looked at cultural distance between major world religions in the World Values Survey. What did we find?
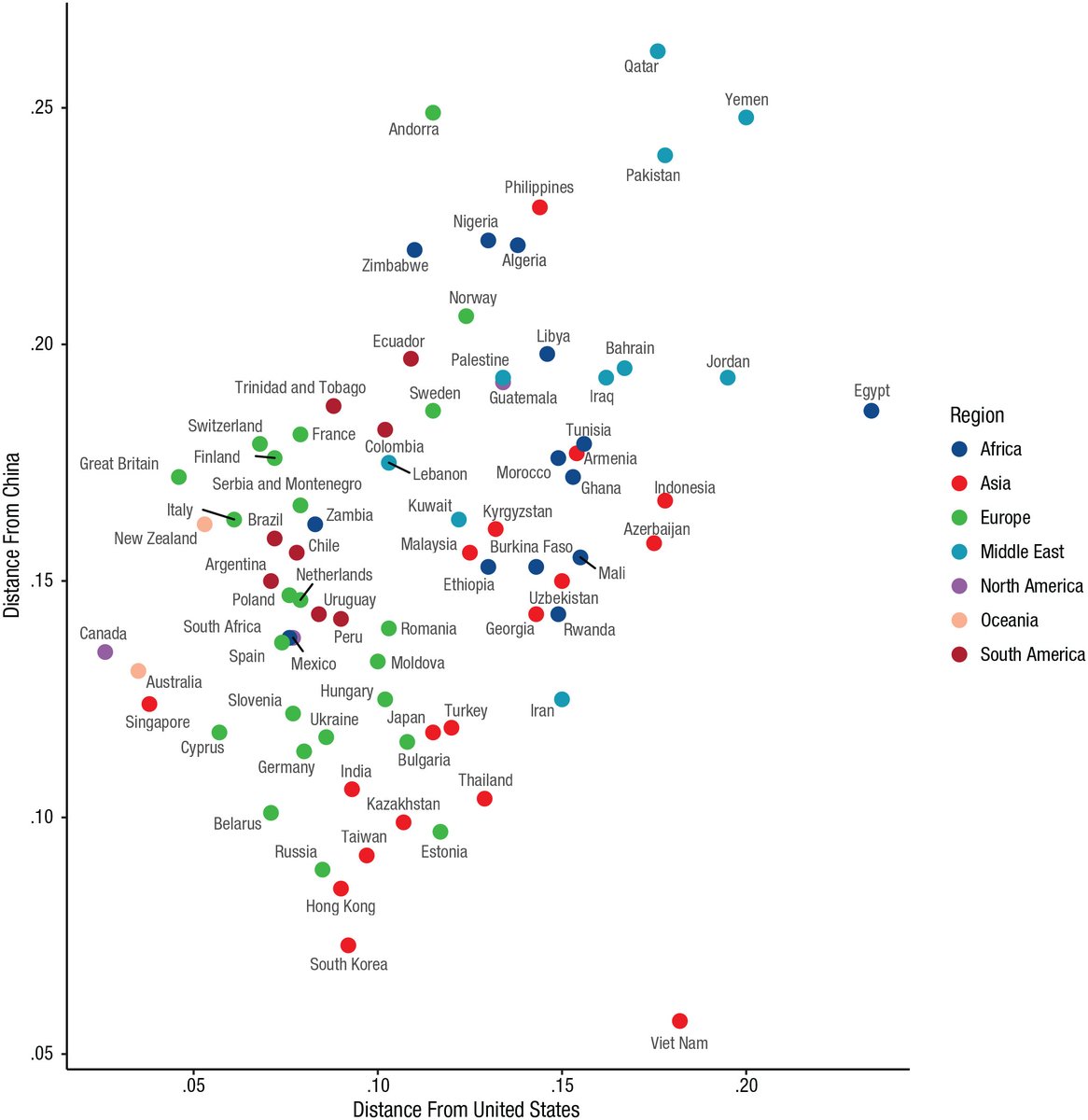
CFst are large enough to have competition between distinct cultural-groups of cultural traits, even if you remove overtly religious beliefs. The “People of the Book”—Christian, Muslim, and Jewish people—share cultural similarities. Christians are about as culturally similar to both Jewish and Muslim people as Americans are to Canadians or Australians are to Brits. But just as the United States is similarly geographically distant from Uruguay and Ukraine, but Uruguay and Ukraine are not geographically close to each other, Jewish and Muslim people are a similar cultural distance as people in the United States and the Philippines.
You can take a look at national cultural distance with this app: https://world.culturalytics.com/
As a side note, Buddhists are interesting. They look like Hindus, as fellow Dharmist, but also like Christians, Muslims & Jews.
But of course, these broad generalizations hide a lot of cultural clustering within countries. Fellow citizens more culturally similar than co-religionists in a different country, but foreigners who share a religion are more similar than those of a different religion. And that similarity is stronger if they’re highly religious.
And this broad generalization was true in our data even for places we didn’t expect. Like Muslims in India and Pakistan.
All of this holds true controlling for religious freedom, geographic, linguistic, & genetic distance.
We also looked at the interaction between national and religious culture, showing that non-American Christians are most similar to Americans. America is still a very Christian country and Christianity might therefore be considered the WEIRDest religion (using America as a proxy for WEIRD). That’s consistent with Joe Henrich’s hypothesis for the role of Christianity in creating WEIRD psychological and cultural traits: https://en.wikipedia.org/wiki/The_WEIRDest_People_in_the_World
And finally, non-Americans with no religious denomination are also similar to Americans without religious traits. That’s consistent with other work showing that the US looks like other secular, developed nations except when it comes to traditional religious values.
Long post, but an important topic that helps to resolve controversies such as IQ differences.
Quick summary: We reconcile behavioral genetics and cultural evolution under a dual inheritance framework. A cultural evolutionary behavioral genetic approach cuts through the nature–nurture debate and helps resolve controversies such as IQ.
Business is booming in behavioral genetics. We’re in the midst of a GWAS gold rush. Powerful computers and sequenced DNA of millions has led to an industrious search for SNPs that correlate with a variety of traits. Some even claim the curse of reverse causality has been lifted.
There’s also been a parallel revolution in cultural psychology and cultural evolution. Genes, culture, and the environment have often co-evolved, shaping our species. But the revolutions in behavioral genetics and cultural evolution have largely been independent. But, given the extensiveness of the cultural and culturally-shaped environment, cultural evolution offers an important but typically missing complement to otherwise insightful methodological and empirical analyses within behavioral genetics. Genes and culture are intertwined. For example, our jaws too weak and guts too short for a world w/o controlled fire & cooked food. It’s obvious that lower environmental variation will lead to higher heritability scores. Less obvious is how culture can mask or unmask genetic variation. Or how diffusion and innovation can increase or decrease heritability. Or how to define a single society for the purposes of measuring heritability, without being able to identify cultural cleavages that can lead to Scarr-Rowe type effects: en.wikipedia.org/wiki/Scarr-Row…
Reconciling behavioral genetics & cultural evolution offers insights for differences in heritability between and within populations, differences in heritability across development, and the rise in IQ (Flynn Effect). We’d like a discussion that nuances common interpretations of the nature and nurture of behavior.
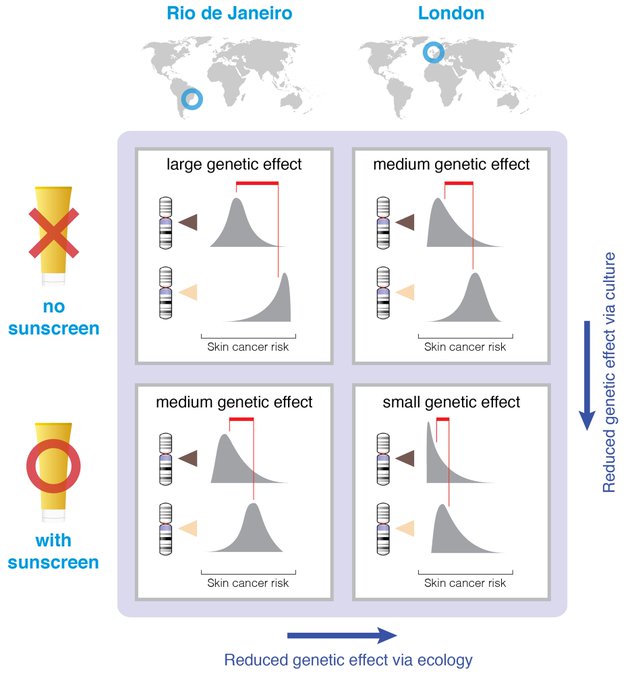
First, let’s quickly get a common misinterpretation of heritability out of the way: Heritability is not an index of the genetic basis of a trait nor a measure of the relative contribution of nature compared to nurture. It’s the proportion of phenotypic variance for some trait that is explained by genetic variance. So obviously variability in genes, in environment, and in traits will all matter. A quick illustration: skin pigmentation and UV levels. Genes affect level of skin pigmentation and propensity for tanning instead of burning; ancestral adaptations to UV radiation at different latitudes.
Migration means melanin is mismatched to latitude: Aussies with European ancestry are more susceptible to skin cancer; Europeans with African and South Asian ancestry have higher rates of vitamin D deficiency.
A Gene×Environment approach won’t predict how heritability estimates change over time as non-genetic adaptations compensate for genetic mismatches: fairer Australians wear sunscreen, a hat, & covered clothing; darker Europeans consume vitamin D supplements & vitamind D-rich or fortified foods. Here it’s easier to see that heritability is a function not only of genes, traits, and ecology, but also of an evolving cultural environment. The environment is not an inert backdrop against which genes should be evaluated. It evolves in relation to both genes and ecology.
Four lessons before we continue. The first is obvious to behavioral geneticists, the second sometimes noted, the third and fourth are typically missing.
Lesson 1
There is no overarching, one-quantity heritability of a trait to be discovered. There is no fixed answer to the question, “What is the heritability of skin cancer?”
Lesson 2
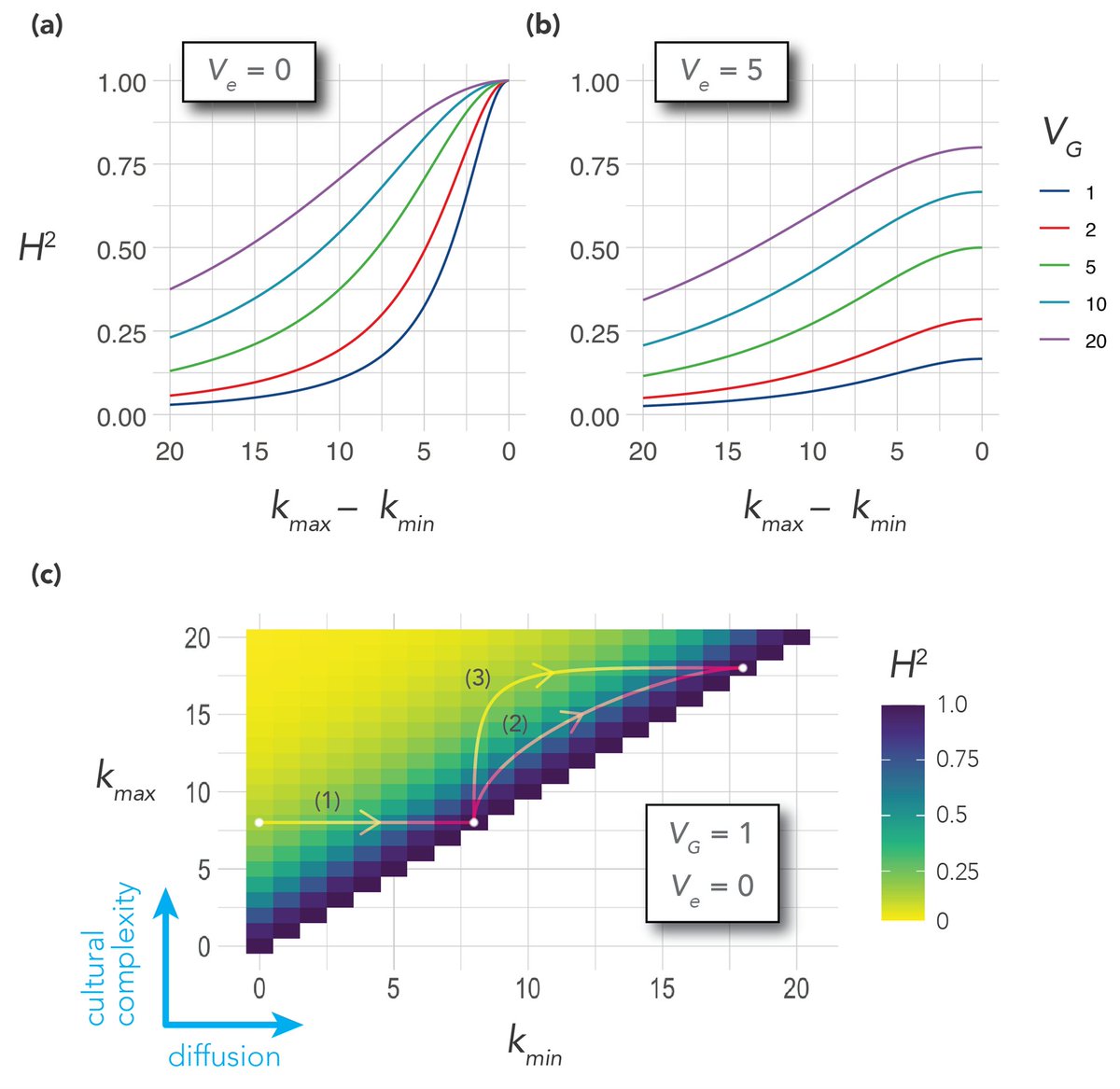
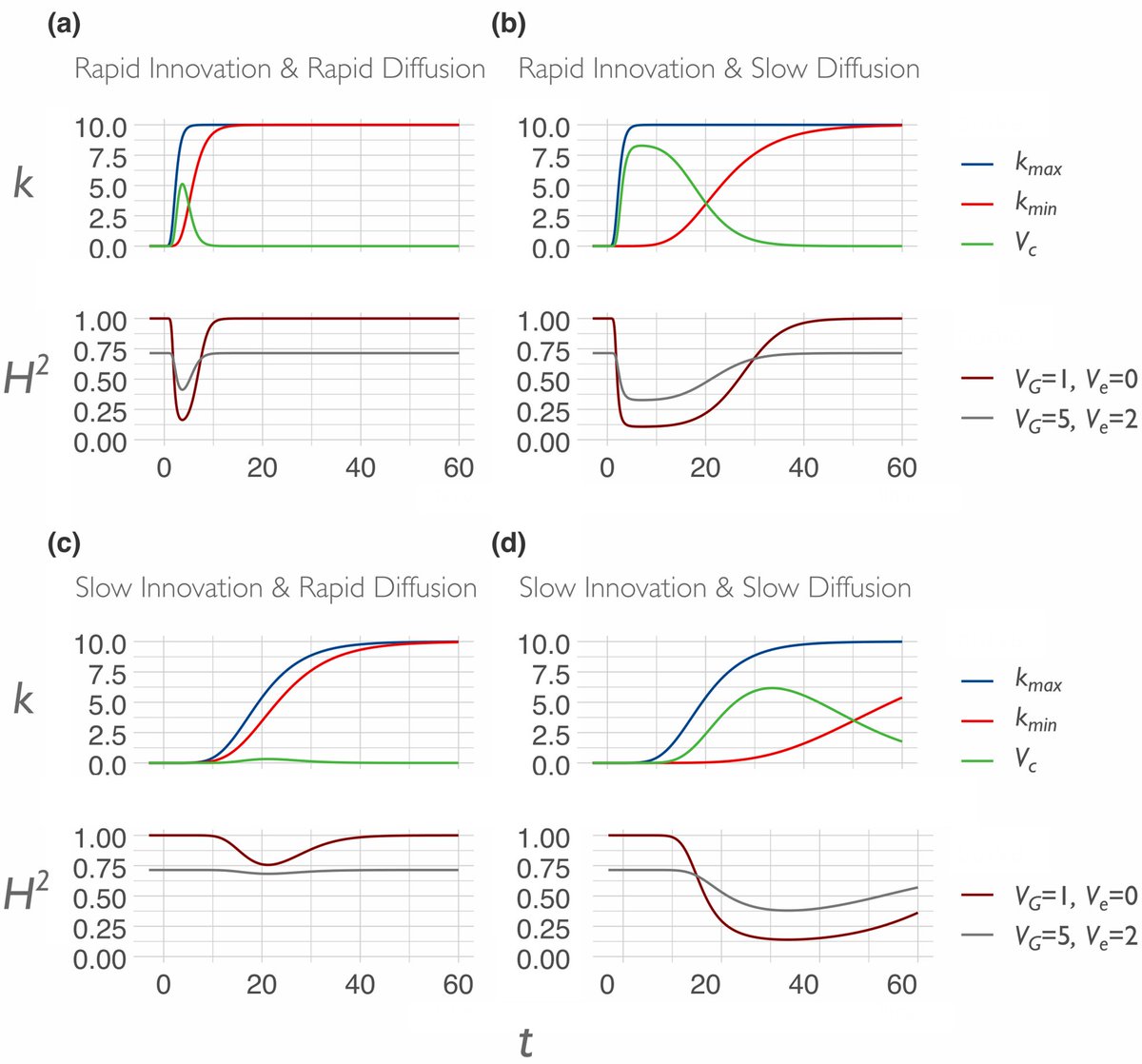
Heritability will depend not only on ecology, but also on culture & specifically on diffusion and innovation—both of which can rapidly change and therefore rapidly change heritability estimates.
Lesson 3
Diffusion and innovation are broadly directional. Cultural diffusion of sunscreen, clothing, shade & sunglasses, and cultural innovation toward more effective screening and treatment of melanomas all work to reduce heritability estimates due to a masking effect.
Were any of these an example of culture unmasking genetic effects, such as tanning salons that induce differential risk according to skin pigmentation level, we would have predicted an increase in heritability.
Lesson 4
We might expect a stronger cultural response where ecological and cultural selection pressures are stronger—skin cancer mitigation in Australia but Vitamin D supplementation in northern Europe. Not been tested to our knowledge, but the predictions are clear.
“Which SNPs are associated with skin cancer?” is similarly culturally dependent. Societies where sunscreen use is common, we expect SNPs associated with skin pigmentation to be less predictive of skin cancer compared to societies where this is not the case.
Similarly, we would expect SNPs associated with antioxidant metabolism to be less predictive of skin cancer in societies whose foods are rich in antioxidants—such as in traditional Mediterranean cuisine.
Section 2.2 is on how cultural evolution shapes heritability through diffusion and innovation. We live on the peaks climbed by cultural evolution – human environments have already been shaped by cumulative cultural evolution—functionally overlapping with genetic evolution.
Diffusion and invention can mask or unmask genes. Examples using language, fertility, and schooling.
Language example
If Cantonese or Yoruba (both tonal) spread, heritability of language ability would increase proportional to variation in “tone” genes.
If Norwegian or Russian (both non-tonal) spread in the same population, heritability of language ability would decrease.
Fertility example
Contraception and social values in 20th century unmasked the effect of genes associated with reproductive behaviors and preferences (heritability rose in US). But a one-child policy or rigid childbearing norms masks the genetic effect.
School example
School is a powerful mechanism for cultural diffusion. Heritability of literacy in:
Australia: Kindergarten: 0.84 Grade 1: 0.80
Scandinavia: Kindergarten: 0.33 Grade: 0.79
Why?
Cultural diffusion of literacy.
Australian children begin receiving compulsory literacy instruction in kindergarten, while in Scandinavia the kindergarten curriculum emphasizes social, emotional, and aesthetic development—literacy instruction only begins in Grade 1.
Assessing the genetic basis of literacy without accounting for particulars of curricula on cultural diffusion is a selection bias of unknown magnitude. Note that literacy in the home environment is already shaped by cultural evolution; there is no ‘baseline’ heritability. Heritability is a composite measure that captures both genes and culture. Saying literacy heritability in Scandinavia jumps up to 0.79 in Grade 1 reveals as much if not more about the disseminative power of modern schooling than it does about the genetic basis of literacy. Similar dynamics with innovation. Read about it in the paper.
However, one neglected factor is “cultural clustering”, where even highly useful forms of cultural knowledge may not easily permeate social barriers. Not necessarily ethnic boundaries, also class, wealth, occupation, political alignment, religion, or incidental geographic layout. Greater differential clustering can lead to a cultural Simpson’s paradox (we’ll get to that shortly, but see Section 3.4).
Cultural FST (CFST) is useful for identifying these clusters. You can read more about that paper here: https://www.michael.muthukrishna.com/beyond-weird-psychology-measuring-and-mapping-scales-of-cultural-and-psychological-distance/
Hopefully, you can see the importance of a cultural evolutionary behavioral genetics. We hope this target article will spark a vibrant discussion. But let’s move onto the problems that obscure the effect of culture:
(1) the WEIRD Sampling Problem
(2) the Hidden Cluster Problem
(3) the Causal Locus Problem
And then describe the:
(4) Cultural Simpson’s Paradox that emerges at their junction.
The WEIRD Sampling Problem
The WEIRD people problem? Pretty bad in genetics too. Twin studies: 94% Western: 60% US, UK, Aus; 25% Nordic 6% Non-Western: 4% China, Japan, South Korea, Taiwan
Remainder of the world, i.e. vast majority of humans are the remaining 2%
Same story in GWAS: 88% European ancestry. 72% from just 3 countries: US, UK, & Iceland 20% from Japan, China, and South Korea
From a cultural evolutionary perspective, given (a) cultural environment, (b) coevolution b/w culture & genes, & (c) cultural differences between populations, not surprising that: 1.Polygenic scores don’t translate well across ancestry groups (European scores, 42% in Africa) 2. Polygenic scores are highly sensitive to inadequately controlled population stratification. And so cultural variation and the hidden cluster problem is pernicious.
Hidden Cluster Problem
Cultural clusters (or segregated diversity) typically created by barriers impeding cultural transmission, such as topography, cultural conflict, language, social stratification by class, wealth, etc. Immigrant countries more clustered (Canada > Japan).
Countries whose borders are drawn arbitrarily with respect to the geographic arrangement of cultural groups, for example by colonial administration (many countries in Africa), are also likely to have high clustering. You can use CFST to find them: https://journals.sagepub.com/doi/abs/10.1177/0956797620916782
Note that cultural clustering is not the same as genetic clustering as we explain at length in Section 3.2.2. Indeed, reconciliation between cultural evolution and behavioral genetics requires an update in the way we think about culture.
Causal Locus Problem
Hidden cluster problem describes complexity that exists w/in social groupings. Culture is not an unstructured exogenous variable. Culture is constructive system that accumulates functional adaptations in a directed manner over time. Two key lessons here.
Lesson 1: Genes that make vs genes that break. The more complex a system, the more ways it can fail. Take the history of lighting.
Wood fire can be extinguished in 2 ways Flourescent bulbs have 7 ways to fail LEDs have 30
Faulty O-ring can explode a space shuttle and so on.
There is a fundamental asymmetry: easier to find ways to break the system than ways to explain or improve it. So too for gene function. All your cells have the same bootstrapped code, but they interact with each other, what they create, and their surroundings to create you.
There are many ways these interactions can go wrong. It is easier to identify deleterious genetic mutations than beneficial mutations. The space of failure is larger than the space of success, making genes that break more detectable than genes that make. For example, a single mutation can cause Mendelian disorders such as cystic fibrosis and Huntington’s disease, but no single mutation creates genius. Over 1000 genes have been linked to intelligence.
Each gene only explains a miniscule fraction of variation in intelligence, and the causal mechanisms are unlikely to be straightforward. In contrast to these genes that make, the causal mechanisms behind single gene mutations that cause intellectual disability—e.g. BCL11A, PHF8, ZDHHC9—are relatively well understood.
Increasing nutrition, improving schooling, and removing parasites have positive effects on IQ, but in a society where parasite infection is kept under control, we would not notice that parasite status correlates with intelligence. And by corollary, genes that provide protection against malnutrition, parasites, or pollution would only be positively associated with intelligence in environments where these insults occur. In environments where these insults have been removed, the same genes would not be associated with intelligence, and can even be deleterious, as with sickle cell trait. Not helpful if there’s no malaria.
Genes are functionally masked by cumulative cultural evolution, and we expect that this masking is extensive and systematic. A quick evolutionary and historical example: Vitamin C, the GLO gene, and dead sailors.
Vitamin C is an essential nutrient and its acquisition is thereby an essential biological function. Endogenous synthesis of vitamin C requires a gene called GLO, and GLO is present across most of the animal kingdom. But because vitamin C synthesis is metabolically costly, the gene is inactive in some species that have access to sufficient quantities of the nutrient in their diets. e.g. taxa such as teleost fishes, guinea pigs, many bats, some passerine birds, monkeys and apes.
Anthropoid primates occupy a frugivorous niche, and fruits often contain sufficient vitamin C. Here gene function is offloaded onto environmental resources. In turn, this offloading has behavioral implications. If a species becomes dependent on its environment for vitamin C, both its behavioral range and evolutionary trajectory become constrained by the availability of the nutrient. Humans are a nice example of this.
As our species migrated across the planet, we found ourselves in environments where vitamin C was in short supply. A deficiency of vitamin C causes scurvy—the bane of seafarers until the trial-and-error discovery that certain food items like sauerkraut and citrus could prevent ships from being packed with tired, bleeding, toothless, and eventually dead sailors.
Masking does not necessarily need to be in the direction from culture to genes: genetic assimilation is same process working in the opposite direction, where a trait that is regularly acquired through learning gradually transfers its locus to the genome (i.e. Baldwin effect).
Cultural Simpson’s Paradox
Which leads us to the Cultural Simpson’s Paradox. Causal Locus Problem can confound the measurement of genetic effects due to Hidden Cluster Problem obscured by WEIRD Sampling problem creating a Simpson’s paradox.
Let’s return to the UV example. The melanin-UV mismatch can be masked by the cultural diffusion of sunscreen, especially in regions with more exposure to sunlight. In other parts of the world, the issue is under-exposure to the sun causing vitamin D deficiency. Low vitamin D leads to lack of bone integrity, muscle strength, autoimmune disease, cardiovascular disease, cancer etc.
In US and France, more north you go, the the lower vitamin D levels. Makes sense, right?
But when we compare across Europe, we see the opposite pattern where people in northern countries have higher vitamin D than people in southern countries. What’s going on?
High consumption of fatty fish and cod liver oil in Northern Europe, as well as greater sun-seeking behavior in these countries compared to Mediterranean Europe. These are potent cultural adaptations.
Participants fed the traditional Norwegian fish dish mølje three times over a span of two days had 54 times the recommended daily dosage of vitamin D. The relationship between latitude and Vitamin D goes one way within a country, and the other way between the countries.
If we had been Martian anthropologists who did not know that the populated landmass known as “Europe” can in fact be broken down into sub-units called “countries”, these examples would be standard examples of a Simpson’s paradox.
In these cases, the paradox occurs when we do not know how to partition the higher-order population (Europe) into lower-order units. Fortunately, we can partition continents into countries, but in other cases, the relevant units is not as easily identifiable. Let’s move on.
We now have enough to make sense of puzzles in behavioral genetics such as (1) differences in heritability across socioeconomic levels, (2) differences in heritability across development, and (3) the Flynn effect.
SES: Heritability of IQ is higher among affluent, high socioeconomic status (SES) households than among poorer, low-SES households in some societies, but mixed in others. Why?
One explanation is ‘reciprocal causation’: genes well suited to a task can better nurture their skills in a wealthier environment than in a poorer environment and this is amplified over time. Maybe, but then why don’t we see the effect in Europe and Australia?
Here’s what we think is going on: in the US, the differences between school and home environments among high-SES households is smaller than among low-SES households. US is a land of variance. Factors such as school lotteries can dramatically affect the cultural input.
In contrast, the cultural environment is less unequal in western Europe and Australia, where, for example, high quality schools are available across SES. Where these two explanations make different predictions is for poorer countries.
Reciprocal causation would predict low heritability in poorer countries. We would predict high heritability where there is equal access to similarly poor schools and household conditions, but low heritability if inequality is high.
Incidentally we predict the opposite between human and animal environmental effects due to social transmission. It’s interesting, but not central. Check out Section 4.1.2. Let’s move onto heritability across development.
Heritability changes over the lifespan. Heritability of political orientation is similar for American identical and fraternal twins from middle childhood up to early adulthood. Right around the age at which American children leave home, this pattern is broken.
Drops for fraternal but not identical. We argue this is due to vertical vs oblique transmission and would predict a different drop off for say Italian or Croatian who leave home past 30.
Flynn effect describes the rise in IQ test scores over time. Largest in countries that have recently started modernizing, and smallest in countries that had attained modernization. No consensus to explain it, but given speed genes obviously unlikely.
We argue its caused by a rapid worldwide increase of cultural practices, technologies. Intelligence is about hardware—genes, parasites, pathogens, pollution, and nutrition affecting health and brain development, but also software—our increasingly complex cultural package.
By this account, not only is the idea of a culture-free IQ test implausible, but so too is the idea of culture-free IQ. Lots to say here. Go read Section 4.3.
Home stretch: Cultural Evolutionary Behavioral Genetics. The thrust of our theoretical case is that human psychology and behavior have a large cultural component that has been changing over history.
Most recently our psychology has been shaped by the advent of writing, numeracy, different types of agriculture, the Industrial Revolution, the Internet, and smart phones.
As new adaptive traits emerge, initially those who possess these traits will have an advantage, as in the case of access to new food sources, better healthcare, more efficient technologies, or easier methods of learning.
But eventually the traits will reach fixation in the population through the processes of cultural diffusion, at least until they are unseated by subsequent innovations. We predict that these cultural dynamics are reflected in heritability estimates.
As any geneticist knows, genetic heritability is a function of the variability in the environment, variability in genes, and variability in the phenotype. There is little to predict if the phenotype is homogenous, as in the number of fingers or kidneys.
There is little to predict with if the environment or genes are homogenous. But what is factored into the environment includes not only the physical ecology, but also the cultural environment.
While variance in genes and ecology may be relatively stable, the variance in the cultural environment is continually changing through the processes of cultural evolution. A genetic account of human psychology and behavior must also account for culture and cultural evolution.
Section 5 and the conclusion tie everything together, but I’ll leave you to read it (muth.io/cegh). There’s a formal model with some pretty graphs in the Appendix:
We review interdisciplinary evolutionary psychology that takes seriously both our primate heritage and our uniquely cultural nature – a “cultural evolutionary psychology”. Why, how, when, and on which things do different humans work together?
Humans in all societies cooperate far more than other mammals. We’re more prosocial than nonhuman primates who often look like rational choice models (these models are like Hardy-Weinberg models – null models without the effect of evolving norms & other culture).
A more complete explanation needs to explain scale, intensity, and domain differences between societies-people cooperate on different things to different degrees. Need to explain the scaling up in the last 12k years. And that many mechanisms can support maladaptive behav.
Explanations like language, intelligence, & institutions are insufficient. We can use language to lie, our cognitive abilities to cheat, & institutions can be undermined by lower scales of cooperation. Where did these come from anyway? See the cultural brain hypothesis & the collective brain. Also summarized in this lecture:
We use cultural evolution, dual inheritance theory, and the extended evolutionary synthesis as our theoretical framework & evaluate connected theories and evidence. For approach, see: https://www.nature.com/articles/s41562-018-0522-1 … (summarized).
Social norms and institutions – their origins and evolution is key to explaining the 4 features / puzzles of human cooperation mentioned before.
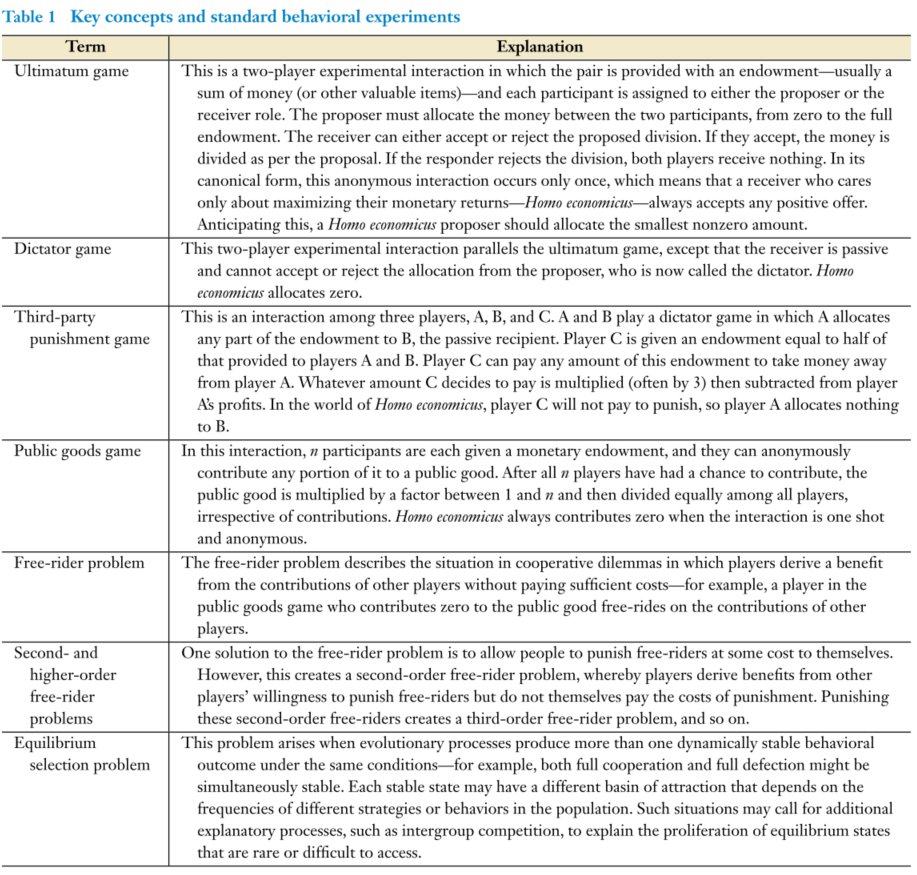
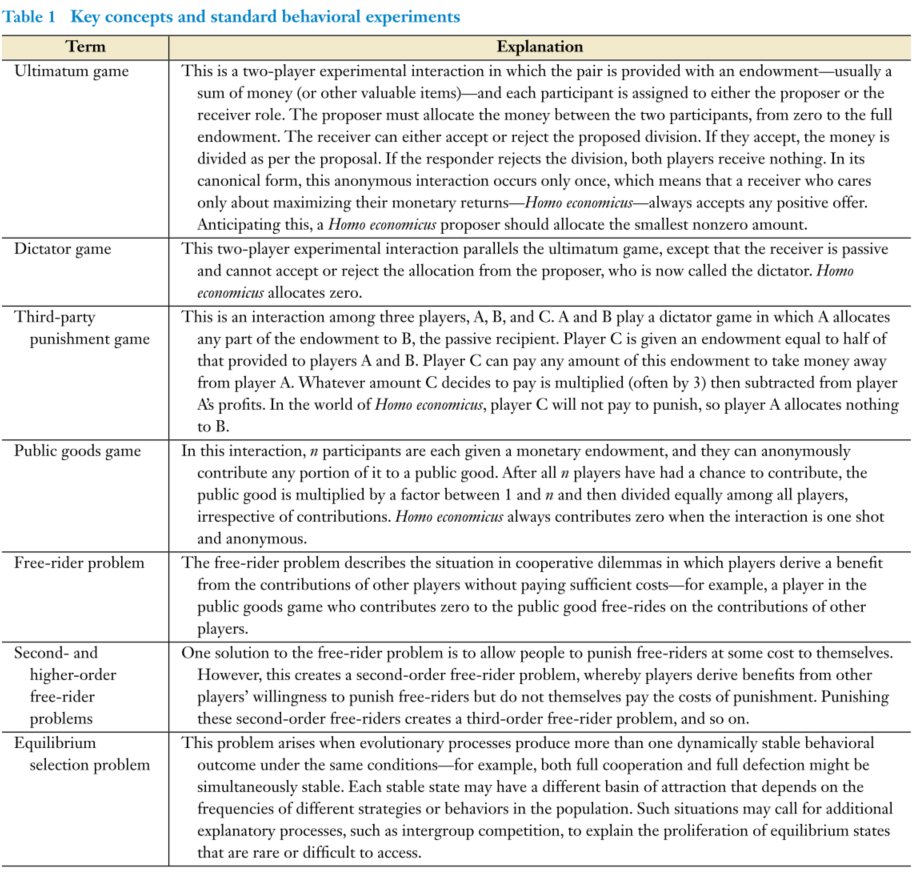
Some key concepts and behavioral experiments in cooperation.
Social norms shape cooperation, differ b/w societies, kids copy adults. Fairness is not the same everywhere – e.g. inequity aversion is not universally symmetric. We don’t like when things are unequal and we have less, but folks differ on unequal where they have more.
We review key mechanisms in broad strokes: kin-based, direct reciprocity, reputation, punishment, signaling. Origins of institutions. WEIRD intuitions are not a good guide – take partner choice for example.
So you have societies with different norms & sustained by different mechanisms of cooperation. Which ones spread? Competiton w/ sufficient resources can favor higher scales, but lower scales can undermine higher scales – corruption or autocracy or insurrection etc. Need alignment between levels.
The mechanisms of cooperation discussed are not alternatives to this competition. They are solutions to the free-rider problem with limits on scale and that can undermine one another. You also need to solve the equilibrium selection problem.
Social norms can create selection pressure on genes, they can self-domesticate. Institutions as connected and sometimes formalized social norms can create interdependence and fusion. They can align interests.
We end by revisiting the opening challenges. Check out the paper here:
New paper on “Psychology as a historical science” in Annual Review of Psychology. Catalyzing the field of “historical psychology” by reviewing work on: origins of psychology and institutions today, psychology of the past (data from dead minds).
Our psychology is shaped by our societies, and our societies are shaped by their histories. We can do better than butterfly collecting–just measuring cross-cultural diffs. For psychology to develop a full theory of human behavior, we need historical psychology.
Psychology is shaped by millions of years of genetic evolution, thousands of years of cultural evolution, & a short lifetime of experience; yet, much of the field has focused on that short lifetime of experience. The WEIRD People Problem is not only about geography but history.
Past societies can be as culturally distant as distant societies. Cohort effects are a sliver of the cross-temporal variation we would expect in a culturally evolving species. History serves as a kind of psychological fossil record, a source of “data from dead minds”.
We (1) review work in historical psychology; (2) introduce methods including causal inference & how to extract data from dead minds; (3) explore the role of theory in mapping history to psychology; and (4) provide some conclusions concerning the future of this field.
E.g.s: Religious evolution & social psych. Some gods gained the ability to see into hearts & control an afterlife contingent on compliance. In many large-scale societies, these gods became omniscient, omnipotent, & omnibenevolent, coevolving with the scale of their societies.
This historical theory makes predictions not only about expected relationships in the historical record but also about expected contemporary cross-cultural diversity in religious beliefs and cognition. In doing so, the theory links historical psychology to cultural psychology.
WEIRD Psychology may have its origins in suppressing kin networks, changing family structures, & related via one particular religion: The Catholic Church
Institutions rest on invisible cultural and psychological pillars. E.g. a constitution’s proclamations are irrelevant without a belief in the rule of law, or norms of punishment for violations of this rule.
We discuss the importance of causal inference techniques in historical psychology: instrumental variables, difference-in-differences, regression discontinuity. Some e.g. use for slavery & trust in strangers; agriculture & sex diff, gender inequality, collectivism; personality.
Historical psychology includes the psychology of the past – data from dead minds, cognitive archeology. Historical databases are emerging. But sometimes the data is qualitative requiring tools like text analysis.
We discuss some examples of the importance of theory. A society has codependent norms, values, beliefs, behaviors, and institutions. If one takes an exploratory approach and looks for correlations in history, there are many to be found. Theory helps clarify causality.
Collaboration between psychologists, historians, and other humanities scholars is important (see religiondatabase.org for an e.g.). We discuss challenges & strategies.
Taking history seriously is a critical part of moving beyond the WEIRD people problem and making psychology a genuinely universal science of human cognition and behavior.
Diversity is a double edged sword. Governments and organizations often push for greater diversity and tolerance for diversity, because the human tendency is toward squashing difference and selecting others like ourselves. But diversity can both help and harm innovation.
On the one hand, there’s intellectual arbitrage: discoveries and technologies situated in one discipline that draw on a key insight from another. Here diversity is a fuel for the engine of innovation.
On the other hand, diversity is, by definition, divisive. Without a common understanding, common goals, and common language, the flow of ideas in social networks is stymied, preventing recombination and reducing innovation. How do we reap the benefits without paying the costs?
Consider the challenge of collaborations between scientists and humanities scholars (or even between scientists in different disciplines). The key is to find common ground through strategies such as optimal assimilation, translators and bridges, or division into subgroups.
Resolving the tension between diversity and selection is at the core of a successful innovation strategy. And there are many possible solutions.
Some dimensions of diversity matter more than others—without a common language, communication is difficult. On the other hand, food preferences create little more than an easily solved coordination challenge for lunch.
But between these are many dimensions where optimal assimilation may be desirable and traits can be optimized, such as psychological safety so people feel free to share unorthodox ideas.
Other strategies include interdisciplinary translators. In my role at the Database of Religious History (DRH)—a large science and humanities collaboration—we have benefited from a few scholars trained in both to bridge the gap.
Innovation can also be divided into independent groups, coordinating within the group but competing against others trying different strategies (e.g. competition between firms).
Check out the full issue here: https://www.nae.edu/244665/Winter-Issue-of-The-Bridge-on-Complex-Unifiable-Systems
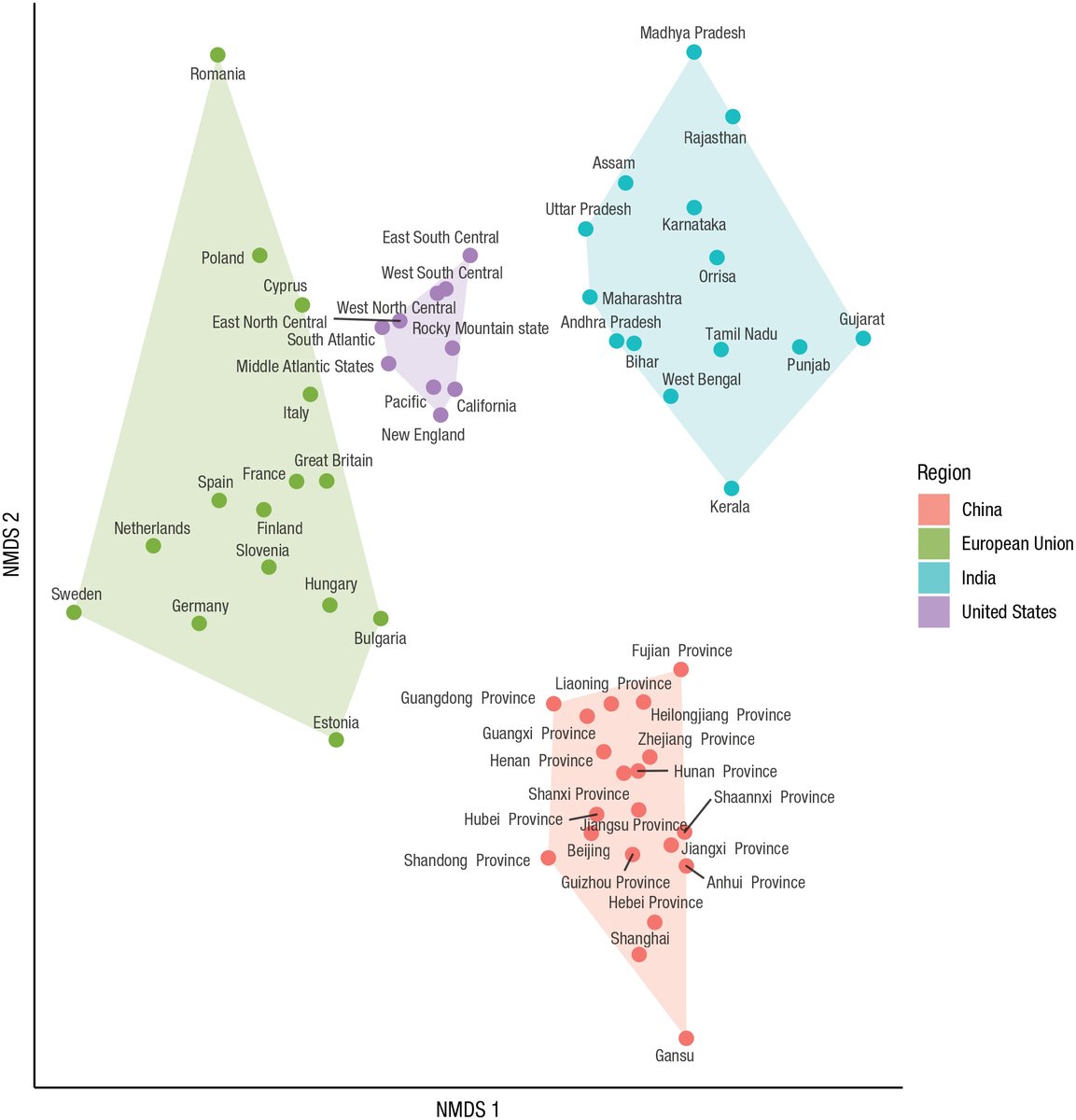
How psychologically and culturally distant is the US from Canada? China from Japan?
2/ CFst is a lens for looking at differences between and within populations. It’s flexible, robust, and theoretically-meaningful.
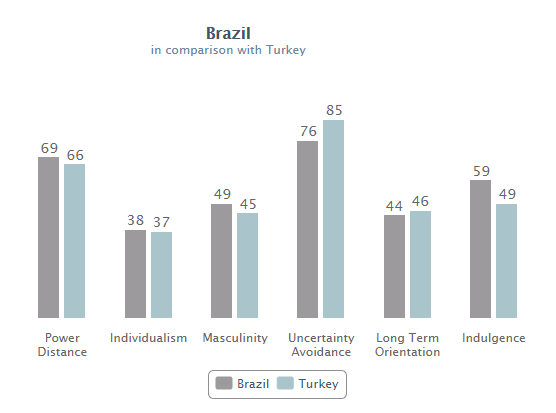
Issue with existing approaches: 1. Societies are distributions of traits. Mean estimates are misleading. Brazil looks like Turkey on Hofstede:
2. Variance captures some of this (Turkey is culturally tighter than Brazil), but how do you capture nominal traits like political priorities: “give people more to say”, “maintain order in the nation”, “fight rising prices”, or “protect freedom of speech”?3. Genetic distance is a proxy, but can be misleading: Hong Kong is more than an order of magnitude more genetically similar to China than to Britain, but is culturally similar to both due to Britain’s century-long history in Hong Kong.4. Linguistic distance is better, but the resolution is low. Difficult to distinguish the cultures of Australia, Canada, the UK and the US, all of whom speak English.3/ Fst is theoretically meaningful within evolution: measures how genotype frequencies forsubpop differ from expectations if there were random mating over the entire population. i.e. it measures the degree to which the populations can be considered structured and separate.4/ For cultural inheritance, this is directly analogous to between-group differentiation caused by selection, migration, and social learning mechanisms.5/ Cultural FST (CFst) is calculated in the same manner as Genetic FST, but instead of a genome, we use World Values Survey as a “culturome”. Questions as loci. Answers as alleles.
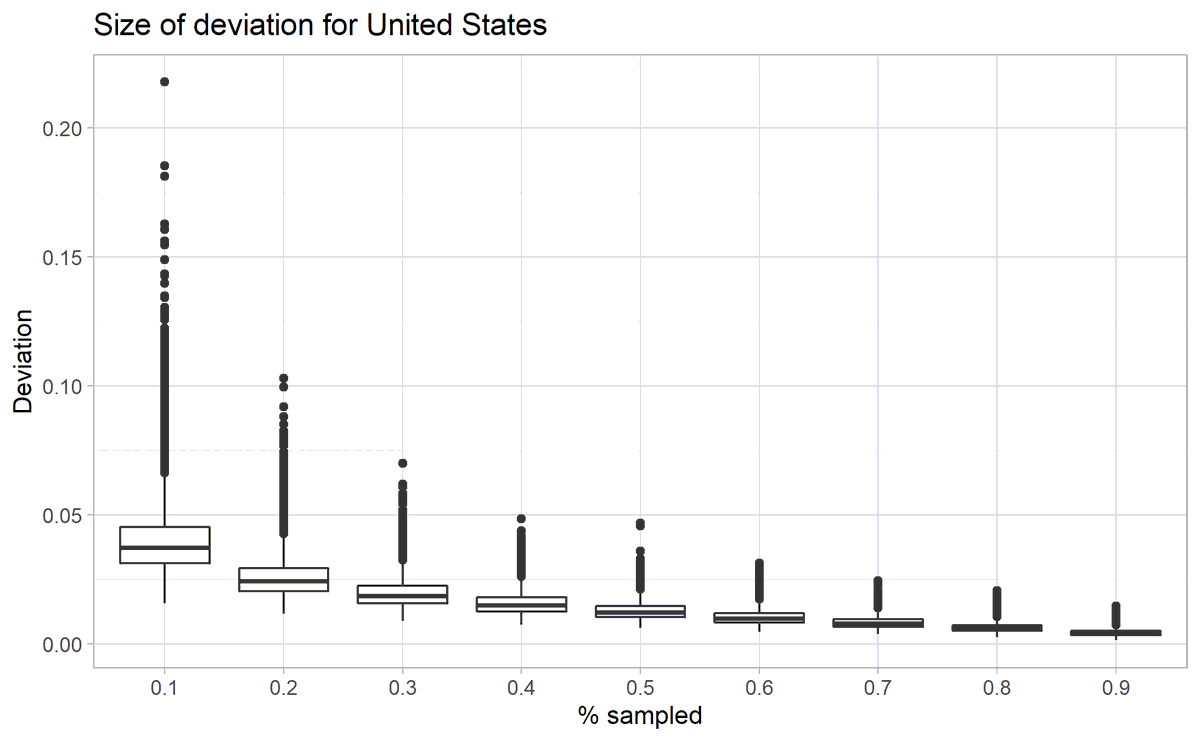
CFst can handle continuous, binary, or nominal traits.6/ Because traits tend to cluster within a society, it’s also robust to missing questions or data. You can drop even 50% of data or questions and get very little deviation.
Even if we don’t ask every conceivable question, if you ask a broad range, you’ll get a similar answer.
Note: Traits cluster within, but not necessarily between societies. 7/ We create an American scale (useful as a proxy WEIRD scale) and a Chinese scale as an example.
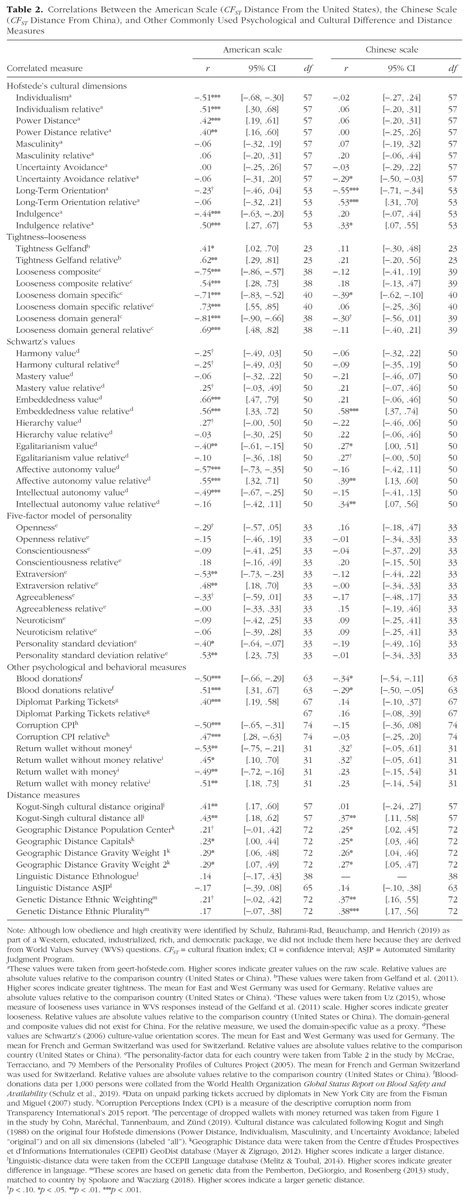
8/ American scale correlates with cultural dimensions, tightness, values, extraversion and personality variance, and many behavioral measures: blood donations, diplomat parking tickets, corruption perceptions, honesty in the wallet drop study:
9/ The Chinese scale is less predictive – why? Two possibilities:
1. WEIRD nations are truly psychological outliers in some objective sense. Plug for @JoHenrich ‘s brilliant new book: amazon.com/WEIRDest-Peopl…
2. Psychological measures have been studied because they are remarkable to WEIRD researchers.
If psychology was dominated by Chinese psychologists, we would see a different set of psychological outcomes covered in textbooks. 10/ Resolving which of these explanations is correct will require greater diversity in both researchers and samples.11/ Final caveats: 1. Similar distance from US / China does not mean cultural similarity. Japan & Norway are similarly distant from US, but are not necessarily similar to each other.
Like Colombia and the UK are similarly geo distant from US but nowhere near each other.
Culture is a large n-dimensional space. 2. The US is relatively homogeneous (note, it’s a loose country, but similarly loose in all regions relative to other large populations). Societies are not homogeneous. They have multivariate distributions of many traits along many dimensions with structure within structure.
There are likely to be cultural differences between not only regions within a country but also ethnicities, religions, socioeconomic class, and other groupings. These are all avenues for future research. 3. We need more data from the Middle East and Africa! We have every reason to suspect the American scale will continue to stretch as we map out these psychological terrae incognitae.These regions (and others like South Pacific) are a treasure trove for the next generation of cultural psychologists. Not just about psychological outcomes, but also questions we ask, and way we organize psychology. What we know is the tip of the iceberg of the human psyche. END I lied. There’s also a website: culturaldistance.com
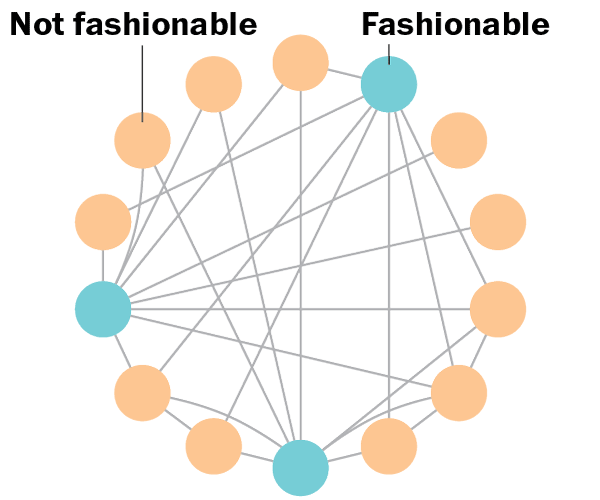
New paper in Personality and Social Psychology Review (PSPR): Societies more susceptible to social learning (e.g. China) more culturally stable, but also more susceptible to rapid transformation. Punctuated cultural equilibrium. Models differences in cross-cultural social networks and influence. Why? 1/3
Consider Majority illusion (Blue Fashionable will be perceived as majority view due to social network structure).
Some societies more likely to conform. Under most conditions, conforming to the majority leads to stability, but… 2/3
A well connected ideologue taking advantage of that conformity leads to rapid social change.
In a less well connected society with fewer conformists, too many leaders, not enough followers making it harder for one to dominate and kickstart a country-wide revolution. 3/3
New paper in Nature Human Behaviour: we argue that the replication crisis is rooted in more than methodological malpractice and statistical shenanigans. It’s also a result of a lack of a cumulative theoretical framework:
The present methodological and statistical solutions to the replication crisis will only help ensure solid stones; they don’t help us build the house. Preregistration and multiple replications(this time with larger samples!)are great, but a solution to decades of distrusted data?
Science is an abductive process with incomplete data and large to infinite space of hypotheses. Better theory can far reduce the possible or likely hypotheses and offer explanations we might not consider based on the data alone.We can’t build a cumulative science by narrowing it down with guesswork, folk intuitions, verbal logic, or our own limited (and largely WEIRD) life experience. Testing these WEIRD intuitions on WEIRD participants can be circular and misleading. Leads to general understanding?We present Dual Inheritance Theory as an example of a more systematic theoretical approach with more constrained predictions. Theory is another way to constrain researcher degrees of freedom.We deal with some common critiques and concerns at the end. Other sciences, the solid findings, applied sciences, and we’re not trained to think this way.
Here’s more critiques and concerns. Can we solve this with neuroscience, Bayesian stats, and Big Data?
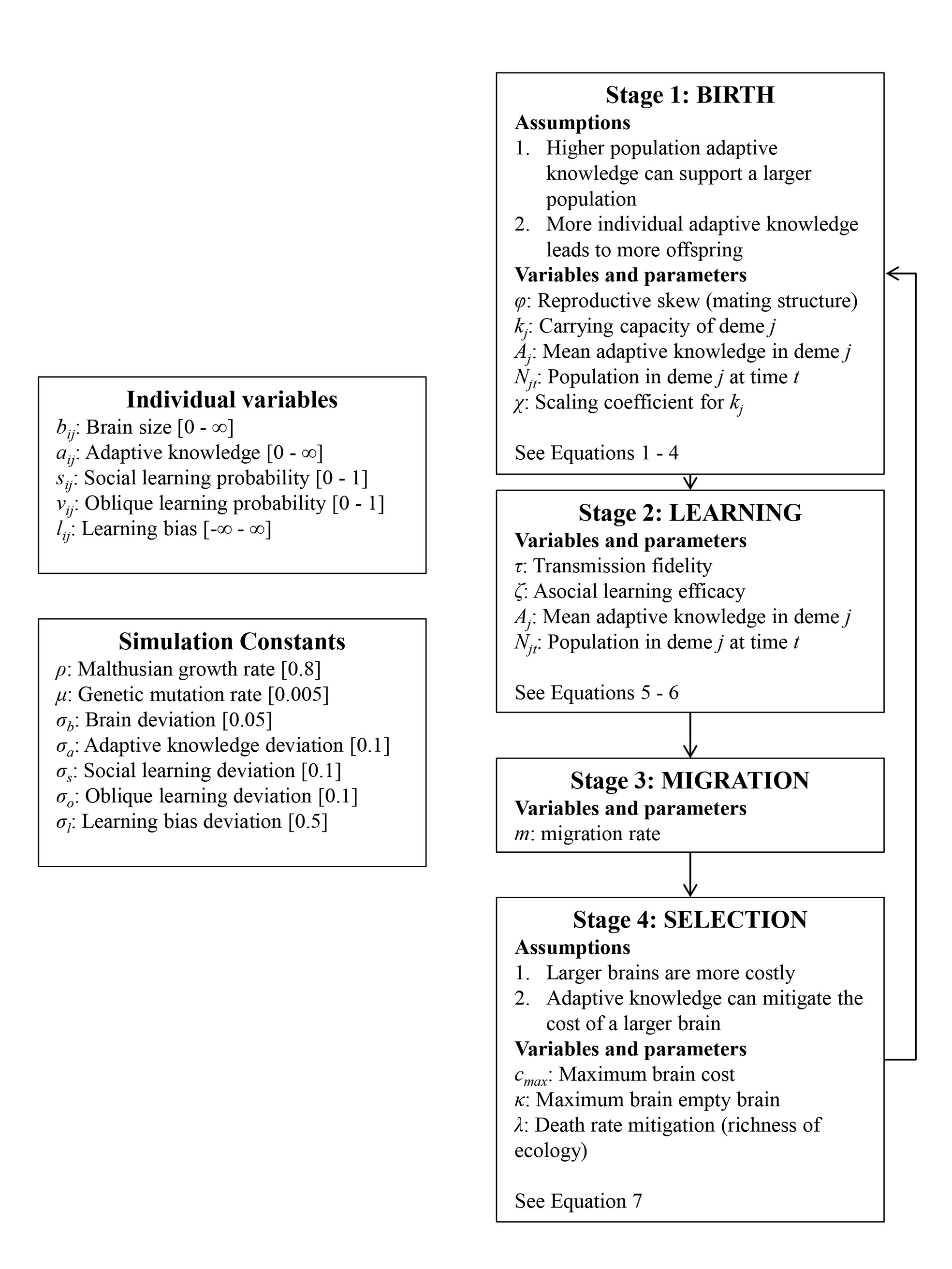
The Cultural Brain Hypothesis is a more general theory for brain evolution across species that unifies more specific explanations around environmental hypotheses and social brain hypotheses. The theory is formalized using an analytical and a computational model.
Figure 1 from paper
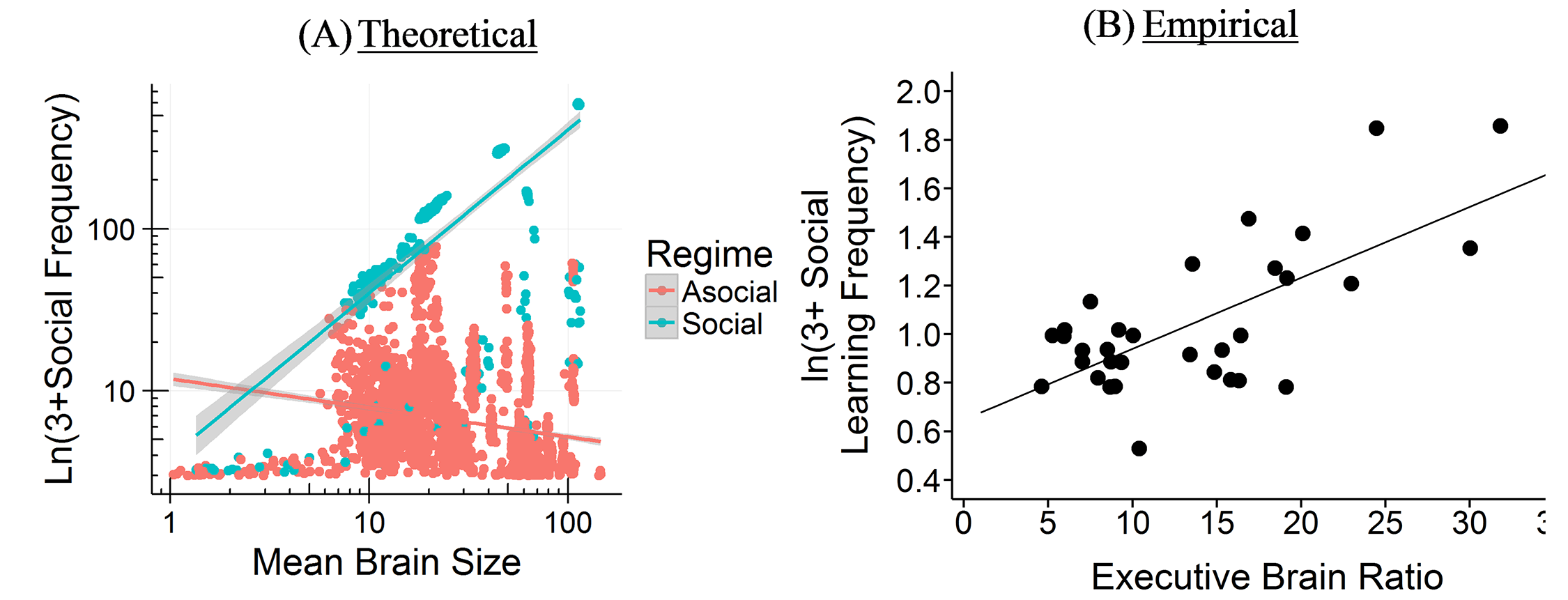
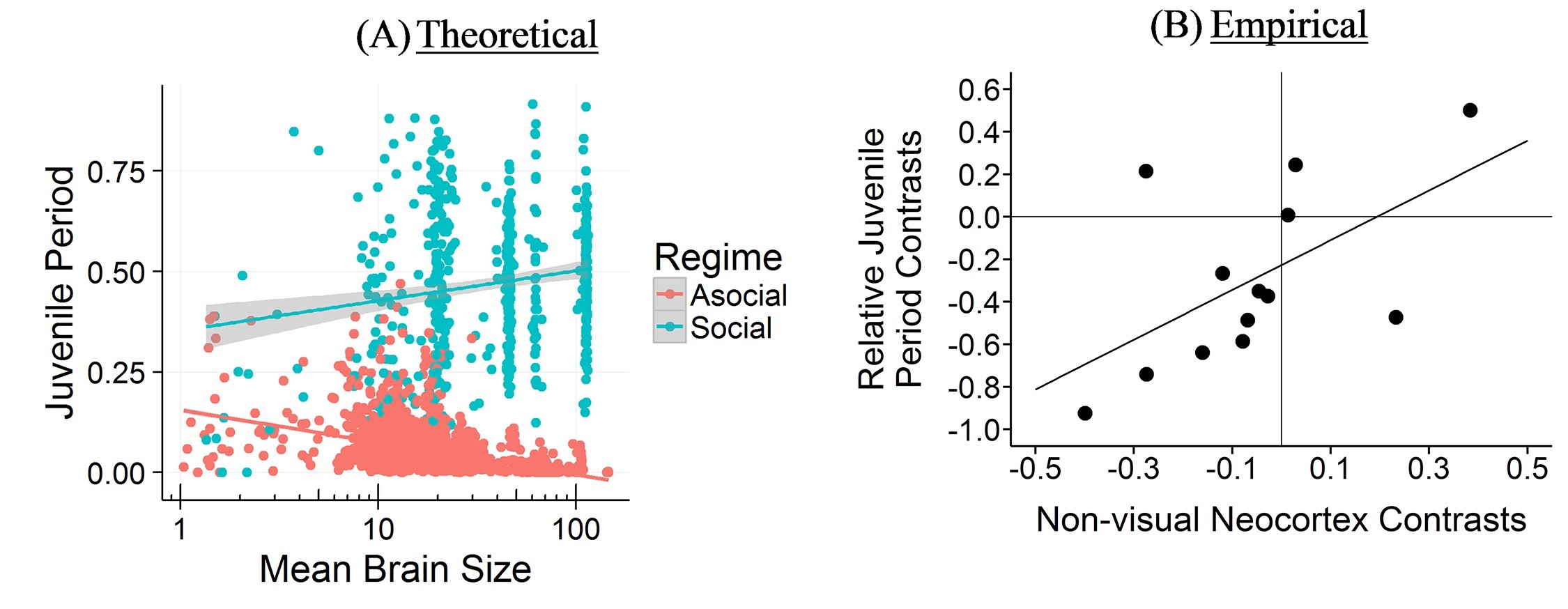
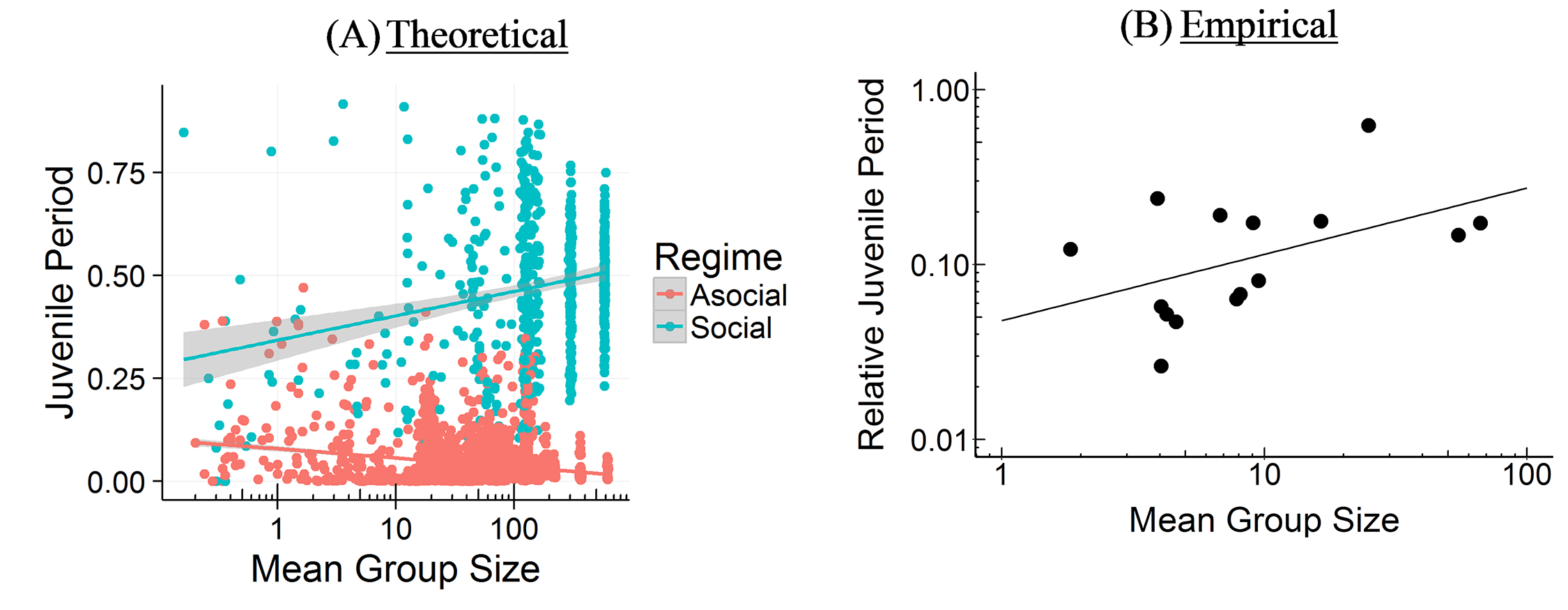
The CBH shows how the environment constrains evolution and how social factors are necessary infrastructure for more social learning species. It predicts different relationships between brain size, sociality, mating structure, the length of the juvenile period, innovation and knowledge, and social learning strategies.
Table 1 from paper.
According to the CBH, the environment constrains brain evolution rather than driving it – brain size is affected by the environment, because you need to have enough calories to feed your brain. But your ability to derive calories from what’s available (or potentially available) is driven by how smart you are – how much information you have. All else being equal, a lush rainforest will have larger brains than an arid desert.
The model specifies two pathways for acquiring this information, both of which can lead to bigger brains – asocial learning and social learning (or some combination of these). If you take the asocial path, you’re reliant on your own intelligence and you don’t have to worry about the social infrastructure. Asocial brains can be larger depending on how easy it is to learn things asocially, but they’ll tend to be smaller than social brains on average.
If you take the social path, it requires all kinds of social infrastructure – more tight-knit and perhaps larger group to learn from, a longer juvenile period, more care during that longer juvenile period, tolerance for other members of the group, an ability and proclivity to learn from other members of the group, and so on. Culture is socially transmitted information, which is a cheaper and more efficient way to get information than asocial learning, but does require all these social factors.
The theory links together ecology and social factors and shows how constraints for learning culture and information in general are what drive the expansion in brain evolution (rather than adaptations to the environment or social factors directly). The model allows us to make sense of a lot of puzzling relationships between brain size, sociality, mating structures, juvenile period, innovation, knowledge, and social learning strategies, and other social and environmental features. We’ve tested some of these relationships among cetaceans and in this paper, we compare it to tests in primates. Unfortunately, most of the focus has been on the more interesting more social learning species (you publish papers by showing how animals and babies are smart and human adults are dumb, not vice versa). The next step is to try to test the predictions for more asocial taxa.
The Cumulative Cultural Brain Hypothesis (CCBH)
The CCBH is a narrow set of parameters that can lead to a take off where information and technology start accumulating faster and faster forcing brains and social factors to evolve to keep up. In our species, our brains continue to grow to the point where we end having trouble giving birth to our babies (larger heads are more difficult to birth), we give birth to our babies prematurely relative to other animals (compare a human infant to a gazelle ready to run). This leads to strategies to take care of our now helpless infants, like forcing fathers to pay for childcare or stick around, and normatively controlling female sexuality so dad knows it’s his. We do other things to keep up. We divide up the information, leading to a division of information and a division of labor (specialization), which can lead to a collective brain. We expand our juvenile period, so we spend longer in childhood, and have an extraordinarily long period of adolescence (the time between when you can reproduce and when you actually do), just to keep learning the ever growing body of information needed to outcompete other members f our group. This last strategy is now at the point we’re hitting a new biological limit – not in the size of the brains we can birth, but in our ability to reproduce at a later age. (I wrote a bit about this for MoneySupermarket in reference to why it takes longer to buy a house).
According to the CCBH, this take off requires:
High transmission fidelity. This could include more cognitive abilities like gaze tracking, shared intentionality, theory of mind, the ability to recognize, distinguish, and imitate potential models, but also more social factors like social tolerance, and ever more sophisticated methods of teaching (consider how long you’ve probably spent in formal education plus internships or low paid entry-level jobs).
Low reproductive skew. Consistent with a “monogamish” or cooperative breeding structure that suppresses reproductive skew. A cooperative breeding environment would have also been ideal to allow for an easy transition to oblique learning. Chimps learn from their mom, but having multiple moms and dads means you can focus on who’s better rather than who you have access to.
Smart ancestors. There is an interaction between transmission fidelity and efficient individual learning. Social learners benefit from smart asocial learners who’s knowledge they can exploit.
Rich ecology. There have to be potential returns in the environment. That is, there are large game or good sources of calories, only requiring the knowledge to acquire them.
There’s more in the paper, which I encourage you to read.
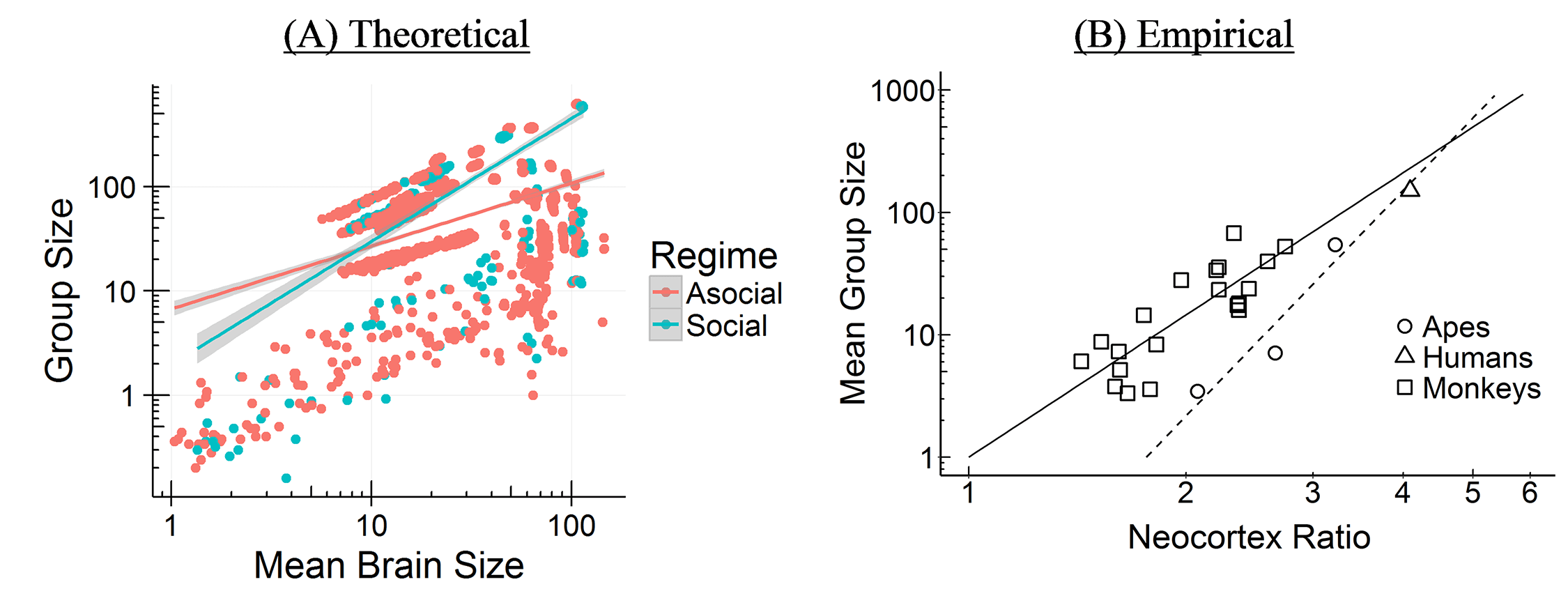
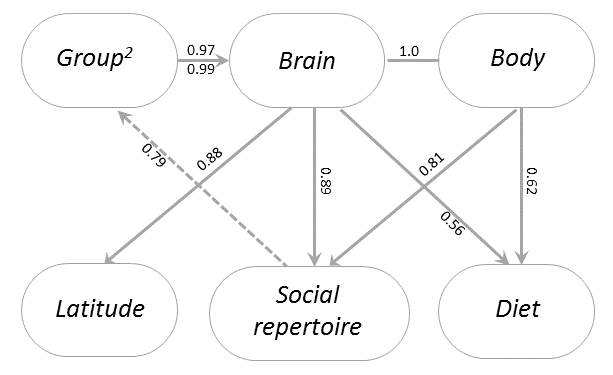
Last week, my paper with Kieran Fox and Susanne Shultz was published in Nature Ecology and Evolution. The paper was a multiyear project, which consisted of countless hours spent poring through marine mammal literature to create the most comprehensive database of cetacean physiology, social structure, life history, and behavior to date. We then used this database to test some of the predictions of the Social Brain and Cultural Brain Hypotheses. Some of the confirmations of these predictions are shown in Figure 3 of the paper below.
Cetaceans represent a great test for the Social Brain and Cultural Brain Hypotheses (CBH), because of how evolutionarily alien these species are, and how strange their underwater world is compared to the world we inhabit. We have previously tested the CBH predictions with primates, but their evolutionary closeness to humans means that the relationships we find may be due to our evolutionary logic or due to these features (such as large brains and high sociality) being present in a common ancestor. Thus finding these relationships in cetaceans is strong evidence for the evolutionary logic. It also sets up cetaceans as an interesting control group for understanding human evolution.
The ongoing massive media response and public interest in marine mammals and the evolutionary sciences was heartwarming. Altmetrics suggested a score of 1026, in the top 5 of articles in Nature Ecology and Evolution, receiving the most attention of recent articles and top 50 of all articles of a similar age. Highlights included several video and audio interviews, including with BBC World News, BBC World Service Radio “Science in Action”, CBC “The Broadcast” (below), and the front page of the print edition of the The Times and front page of the website of The Guardian.
Introducing the possibility of bribes into an institutional punishment public goods game results in reduced contributions.
In an institutional punishment public goods game, stronger leaders result in more cooperation. In our modified “bribery game”, stronger leaders result in less cooperation.
Anti-corruption measures including transparency and tying leaders payoffs to the success of the public good result improve contributions, except if economic potential is low and leaders are weak. Here, they can actually further reduce contributions.
Culture matters. Exposure to corrupt norms via living in corrupt places increases bribes, but having an ethnic heritage that includes corrupt countries, but not having actually lived there yourself results in less bribery.
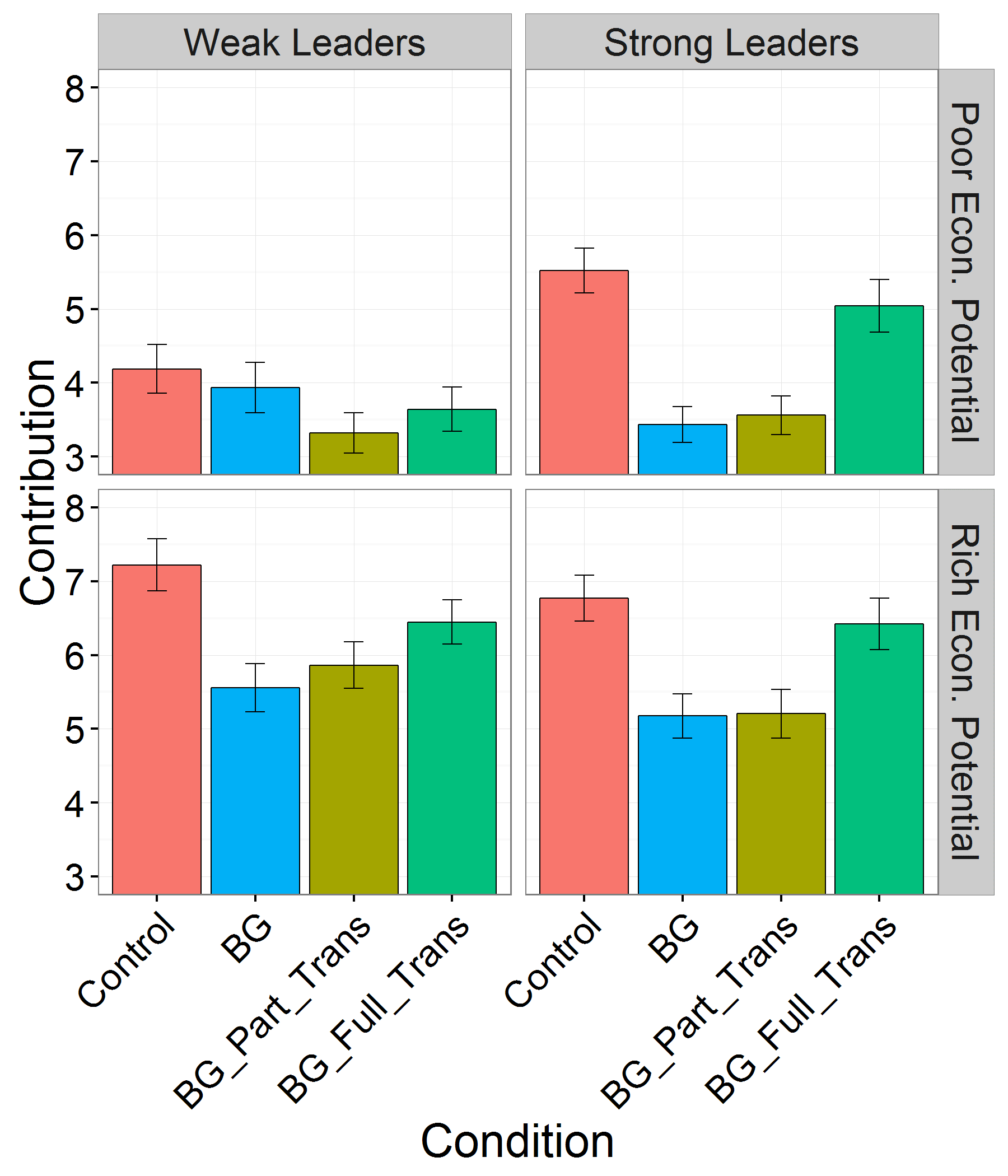
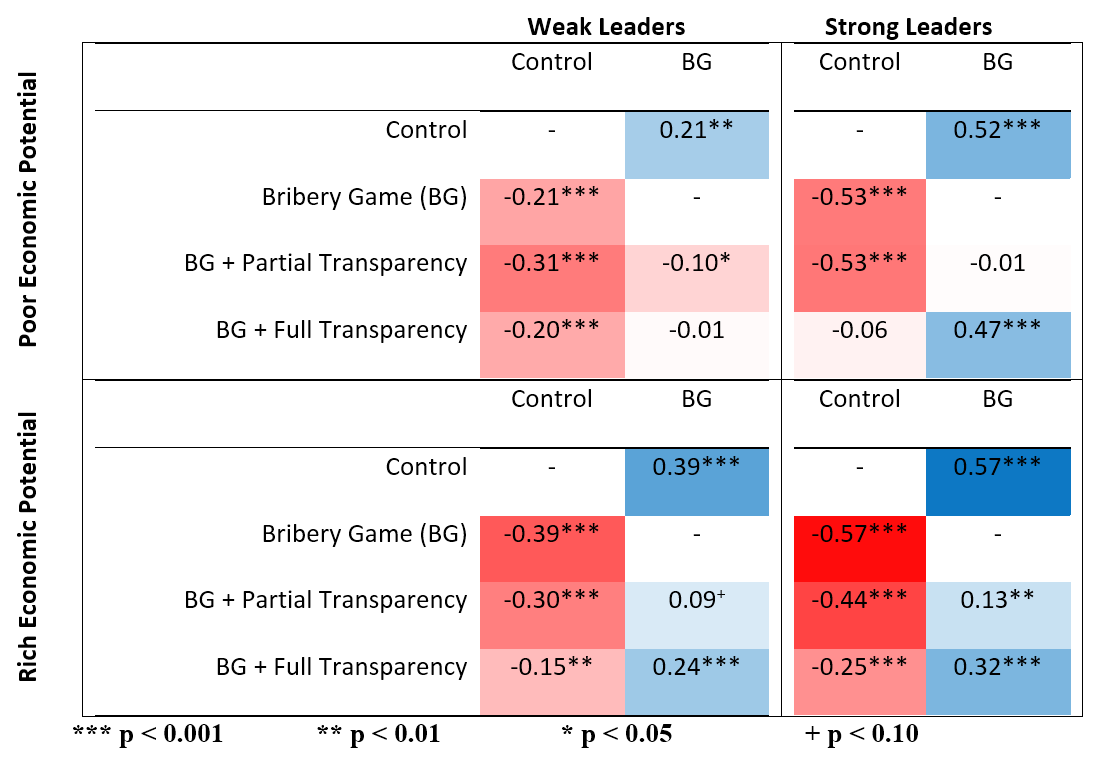
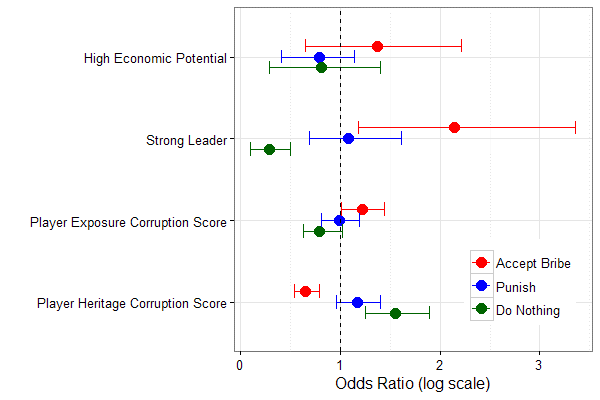
Figures 1, 2 and 3, reproduced below illustrate these results.
Raw contributions (of the ten endowed points) and 95% confidence intervals for each within-subject treatment (control, BG, BG with partial transparency or BG with full transparency) in each between-subjects structural context (strong versus weak leader and poor versus rich economic potential). These data are consistent with our theory that predicts that more powerful leaders increase contributions in the IPGG but decrease contributions in the BG.
Darker blue indicates greater public goods provisioning and darker red indicates reduced public goods provisioning. All coefficients were extracted from a single model by changing reference groups. The columns represent the reference group treatment (control versus BG), while each row shows the coefficient of each treatment compared with this reference group. The contributions were z scores, so the coefficients represent s.d. The full model is reported in the Supplementary Information. In all models, we accounted for the clustering inherent in the experimental design by including a fixed effect for the number of subjects and random effects for participants within groups. Note that in all treatments and structural contexts, the BG has lower contributions than the structurally equivalent IPGG (control). Corruption mitigation effectively increases contributions (although not to control levels) when leaders are strong or the economic potential is rich. When leaders are weak and the economic potential is poor, the apparent corruption mitigation strategy, full transparency has no effect and partial transparency further decreases contributions. *P < 0.10; **P < 0.05; ***P < 0.01; ****P < 0.001.
Odds ratios and 95% confidence intervals are shown for each behaviour (accept bribe, punish or do nothing).
There is nothing natural1 about democracy. There is nothing natural about living in communities with complete strangers. There is nothing natural about large-scale anonymous cooperation. Yet, this morning, I bought a coffee from Starbucks with no fear of being poisoned or cheated. I caught a train on London’s underground packed with people I’ve never met before and will probably never meet again. If we were commuting chimps in a space that small, it would have been a scene out of the latest Planet of the Apes by the time we reached Holborn station. We’ll return to this mystery in a moment.
There is something very natural about prioritizing your family over other people. There is something very natural about helping your friends and others in your social circle. And there is something very natural about returning favors given to you. These are all smaller scales of cooperation that we share with other animals and that are well described by the math of evolutionary biology. The trouble is that these smaller scales of cooperation can undermine the larger-scale cooperation of modern states. Although corruption is often thought of as a falling from grace, a challenge to the normal functioning state—it’s in the etymology of the word—it’s perhaps better understood as the flip side of cooperation. One scale of cooperation, typically the one that’s smaller and easier to sustain, undermines another.
When a leader gives his daughter a government contract, it’s nepotism. But it’s also cooperation at the level of the family, well explained by inclusive fitness2, undermining cooperation at the level of the state. When a manager gives her friend a job, it’s cronyism. But it’s also cooperation at the level of friends, well explained by reciprocal altruism3, undermining the meritocracy. Bribery is a cooperative act between two people, and so on. It’s no surprise that family-oriented cultures like India and China are also high on corruption, particularly nepotism. Even in the Western world, it’s no surprise that Australia, a country of mates, might be susceptible to cronyism. Or that breaking down kin networks predicts lower corruption and more successful democracies (Akbari, Bahrami-Rad & Kimbrough, 2017; Schulz, 2017). Part of the problem is that these smaller scales of cooperation are easier to sustain and explain than the kind of large-scale anonymous cooperation that we in the Western world have grown accustomed to.
So how is it that some states prevent these smaller scales of cooperation from undermining large-scale anonymous cooperation? The typical answer is that more successful nations have better institutions. All that’s required is the right set of rules to make society function. But even on the face of it, this answer seems incomplete. If it were true, Liberia, who borrowed more than its flag from the United States, ought to be much more successful than it is4. Instead, these institutions are supported by invisible cultural pillars without which the institutions would fail. For example, without a belief in rule of law—that the law applies to all and cannot be changed on the whim of the leader—it doesn’t matter what the constitution or legal code says, no one is listening. Without a long time horizon, decisions are judged on how well they serve our immediate needs making larger-scale projects, like reducing the effects of Climate Change, harder to justify5. Similarly, institutions often lack the punitive power to actually punish perpetrators. For example, most people in the US and UK pay their taxes, even though in reality the IRS and Her Majesty’s Revenue and Customs lack the power to prosecute widespread non-compliance; your probability of getting caught is low. The tax compliant majority may never discover that they can cheat or how to get away with it (Chetty, et al. 2013) and they may not actively seek this information as long as the probability of getting caught is non-zero, the system seems fair, and it seems like everyone else is complying. Or in other words, it’s a combination of norms and institutions. But, it gets tricky—institutions are themselves hardened or codified norms6 and the norms themselves evolve in response to the present environment and due to path-dependence of previous environments, past decisions, and the places migrants come from. Modern groups vary on individualism (Talhelm, et al., 2014) and even sexist attitudes (Alesina, et al., 2013) based on their ancestors’ farming practices7. The science of cultural evolution describes the evolution of these norms and introduces the possibility of out-of-equilibria behavior (people behaving in ways that do not benefit them individually) for long enough for institutions to try to stabilize the new equilibria. For a summary of cultural evolution, see Joseph Henrich’s excellent book and for an even shorter summary see this chapter). How do we begin to understand these processes?
The real world is messy and before we start running randomized control trials or preparing case studies, it’s useful to model the basic dynamics of cooperation using a simpler form that gets at the core elements of the challenge. One commonly used model is called the “Public Goods Game”. The gist of the game is that I give you, and say 9 others, $10. Whatever you put into a pool (the public good), I’ll multiply by say 3, but then I’ll divide the money equally regardless of contribution. This is similar to paying your taxes for public goods that we all benefit from, like roads, clean water, or environmental protections. The dilemma is this: the best move is for everyone to put all their money in the pool. Then they’ll all go home with $30. But it’s in my best interests to put nothing in the pool and let everyone else put their money in. If I put in nothing and they put in $10 each, I’ll go home with almost $40 ($10*9*3people / 10 = $37). What happens when we play this game?
Well, if we play it in a WEIRD8 nation, where prosocial norms tend to be higher, people put about half their money in, but as they gradually realize they can make more by putting in less, contributions dwindle to zero. One way to sustain contributions is to introduce peer punishment—allow people to spend some portion of their money to punish other people. This is similar to the kind of punishment we might see in a small village. I know who you are or at least I know your parents or people you know. If you steal my crops, I’ll punish you myself or ruin your reputation. In the game, if we introduce the possibility of peer punishment, contributions rise again. The problem is that this doesn’t scale well. As the number of people grows, we get second-order free-riding—people prefer to let someone else pay the cost of punishment. When someone cuts a queue, you grumble—someone ought to tell that person off! Someone other than me… And you can also get counter-punishment—revenge for being punished. The best solution seems to be to create a punishment institution. Pick one person as a “Leader” and allow them to extract taxes that can be used to punish free-riders. This works really well and scales up nicely. It’s similar to a functioning police force and judiciary in WEIRD nations. In fact, the models suggest that the more power you give to the leader, the more cooperation they can sustain. Aha! Problem solved. Not quite. Models like these are very useful for distilling the core of a phenomenon, they can miss things. Recall where we started—smaller-scales of cooperation can undermine the larger-scale.
In our recently published paper, we wanted to show just how easy it was to break that well-functioning institution. We did it by introducing the possibility of another very simple form of cooperation—you scratch my back, I’ll scratch yours—bribery. And then we wanted to show the power of invisible cultural pillars by measuring people’s cultural background and by trying to fix corruption using common anti-corruption strategies. We wanted to show that these strategies, including transparency, don’t work in all contexts and can even backfire.
Our “Bribery Game” was the usual institutional punishment public goods game with the punishing leader, but with one additional choice—players could not only keep money for themselves or contribute to the public pool, they could also contribute to the leader. And the leader could not only punish or not punish, they could instead accept that contribution. What happened? On average, we saw contributions fall by 25% compared to the game without bribery as an option. More than double what the pound has fallen against the USD since Brexit (~12%9). Fine, bribery is costly. The World Bank estimates $1 trillion is paid in bribes alone; in Kenya, 8 out of 10 interactions with public officials involves a bribe, and as Manfred Milinski points out in his summary of our paper, most of humanity—6 billion people—live in nations with high levels of corruption. Our model also reveals that unlike the typical institutional punishment public goods game, where stronger institutions mean that more cooperation can be sustained, when bribery is an option, stronger institutions mean more bribery. A small bribe multiplied by the number of players will make you a lot richer than your share of the public good! So can we fix it?
The usual answer is transparency. There are also some interesting approaches, like tying a leader’s salary to the country’s GDP—the Singaporean model10. So what happened when we introduced these strategies? Well, when the public goods multiplier was high (economic potential—potential to make money using legitimate means—was high) or the institution had power to punish, then contributions went up. Not to levels without bribery as an option, but higher. But in poor contexts with weak punishing institutions, transparency had no effect or backfired. As did the Singaporean model11. Why? Consider what transparency does. It tells us what people are doing. But as psychological and cultural evolutionary research reveals, this solves a common knowledge problem and reveals the descriptive norm—what people are doing. For it to have any hope of changing behavior, we need a prescriptive or proscriptive norm against corruption. Without this, transparency just reinforces that everyone is accepting bribes and you’d be a fool not to. People who have lived in corrupt countries will have felt this frustration first hand. There’s a sense that it’s not about bad apples—the society is broken in ways that are sometimes difficult to articulate. But societal norms are not arbitrary. They are adapted to the local environment and influenced by historical contexts. In our experiment, the parameters created the environment. If there really is no easy way to legitimately make money and the state doesn’t have the power to punish free-riders, then bribery really is the right option. So even among Canadians, admittedly some of the nicest people in the world, in these in-game parameters, corruption was difficult to eradicate. When the country is poor and the state has no power, transparency doesn’t tell you not to pay a bribe, it solves a different problem—it tells you the price of the bribe. Not “should I pay”, but “how much”?
There were some other nuances to the experiment that deserve follow up. If we had played the game in Cameroon instead of Canada, we suspect baseline bribery would have been higher. Indeed, people with direct exposure to corruption norms encouraged more corruption in the game controlling for ethnic background. And those with an ethnic background that included more corrupt countries, but without direct exposure were actually better cooperators than the 3rd generation+ Canadians. These results may reveal some of the effects of migration and historical path dependence. Of course, great caution is required in applying these results to the messiness of the real world. We hope to further investigate these cultural patterns in future work. The experiment also reveals that corruption may be quite high in developed countries, but its costs aren’t as easily felt. Leaders in richer nations like the United States may accept “bribes” in the form of lobbying or campaign funding and these may indeed be costly for the efficiency of the economy, but it may be the difference between a city building 25 or 20 schools. In a poor country similar corruption may be the difference between a city building 3 or 1 school. Five is more than 3, but 3 is three times more than 1. In a rich nation, the cost of corruption may be larger in absolute value, but in a poorer nation, it may be larger in relative value and felt more acutely.
The take home is that cooperation and corruption are two sides of the same coin; different scales of cooperation competing. This approach gives us a powerful theoretical and empirical toolkit for developing a framework for understanding corruption, why some states succeed and others fail, why some oscillate, and the triggers that may lead to failed states succeeding and successful states failing. Our cultural evolutionary biases lead us to look for whom to learn from and perhaps whom to avoid. They lead us to blame individuals for corruption. But just as atrocities are the acts of many humans cooperating toward an evil end, corruption is a feature of a society not individuals. Indeed, corruption is arguably easier to understand than my fearless acceptance of my anonymous barista’s coffee. Our tendency to favor those who share copies of our genes—a tendency all animals share—lead to both love of family and nepotism. Putting our buddies before others is as ancient as our species, but it creates inefficiencies in a meritocracy. Innovations are often the result of applying well-established approaches in one area to the problems of another. We hope the science of cooperation and cultural evolution will give us new tools in combating corruption.
1 Putting aside what it means for something to be natural for our species, suffice to say these are recent inventions in our evolutionary history, by no means culturally universal, and not shared by our closest cousins.
2 Genes that identify and favor copies of themselves will spread.
4 The United Nations Human Development Index ranks the United States 10th in the world. Liberia is 177th.
5Temporal discounting the degree to which we value the future less than the present. Our tendency to value the present over the future is one reason we don’t yet have Moon or Mars colonies, but the degree to which we do this varies from society to society.
6 Written laws can serve a signaling and coordination function; rather than having to interpret norms from the environment. When previously contentious norms are sufficiently well established, you may do well to codify them in law (legislating before they are established might mean more punishment—consider the history of prohibition in the United States).
7 Not that agriculture is the main reason for these cultural differences!
10 Singapore’s leaders are the highest paid in the world, but the nation also has one of the lowest corruption rates in the world—lower than the Netherlands, Canada, Germany, UK, Australia, and United States [source].
11 Note, there are some conceptual issues that make interpretation of the Singaporean treatment ambiguous. We discuss this in the supplementary. We’ll have to further explore this in a future study. Such is science.
To very briefly summarize, innovation is often assumed to be an individual endeavor driven by geniuses and then passed on to the masses. Consider Thomas Edison and the lightbulb or Gutenberg and the printing press. We argue that rather than a result of far-sighted geniuses, innovations are an emergent property of our species’ cultural learning abilities, applied within our societies and social networks. Our societies and social networks act as collective brains.
Innovations, large or small, do not require heroic geniuses any more than your thoughts hinge on a particular neuron.
We argue that rates of innovation are heavily influenced by:
sociality
transmission fidelity, and
cultural variance.
We discuss some of the forces that affect these factors. These factors can also shape each other. For example, we provide preliminary evidence that transmission efficiency is affected by sociality—languages with more speakers are more efficient.
We argue that collective brains can make each of their constituent cultural brains more innovative. This perspective sheds light on traits, such as IQ, that have been implicated in innovation. A collective brain perspective can help us understand otherwise puzzling findings in the IQ literature, including group differences, heritability differences, and the dramatic increase in IQ test scores over time.
The chapter provides a brief overview of the science of cultural evolution, including its psychological foundations and implications. We discuss how humans evolved a second-line of inheritance, crossing the threshold into a world of cumulative culture. We begin by asking how culture can evolve, dispelling the mythical requirement of discrete genes and exact replication.
Evolutionary adaptation has three basic requirements: (1) individuals vary, (2) this variability is heritable (information transmission occurs), and (3) some variants are more likely to survive and spread than others. Genes have these characteristics so they evolve and adaptive. Culture also meets all three requirements, but in different ways. Like bacterial genes, cultural information spreads horizontally and need not be limited to parental transmission to offspring.
We discuss the evolution of our capacity for culture, asking how and when capacities for culture will evolve (when is cultural learning genetically adaptive).
The answer: culture is adaptive when asocial learning is hard and environments fluctuate a lot, but not too much.
We also outline the evolution of some of our social learning biases (a large part of the third requirement of an evolutionary system):
What moderates these choices (e.g. self-similarity, age, sex, ethnicity; Credibility Enhancing Displays, CREDs).
Some examples in the real world, such as the social spread of suicides (Werther effect) and literally learning better from same-sex and same-race instructors.
Content biases on what to learn: e.g. animals and plants, dangers, fire, reputation, social norms, and social groupings.
Cultural evolution shapes the beliefs and behaviors of groups so that they come adapted to the local environment (including culture) over time, shaping preferences and psychology.
Turning to the population-level, we explain why sociality influences cultural complexity (larger, more interconnected populations have more terms and technologies), how cultural evolution can lead to maladaptive behavior, and how intergroup competition can help eliminate these maladaptive behaviors, briefly discussing the viability of cultural-group selection.
Finally, we discuss how genes can adapt to culture: culture-gene coevolution and how this process may have led to the rapid expansion of the human brain.
Conformist transmission is a type of frequency dependent social learning
strategy in which individuals are disproportionately inclined to copy the most common trait in their sample of the population (e.g. individuals have a 90% probability of copying a trait that 60% of people possess). The bias is particularly important, because it tends to homogenize behavior within groups increasing between group differences relative to within group differences.
Our three key findings across two experiments were:
Substantial amounts of conformist transmission. We found substantial reliance on conformist biased social learning, with only 3% and 9% (or 15%) showing no bias in Experiments 1 and 2, respectively.
Increased social learning and stronger conformist bias as the number of options increased. Both the amount of social learning and the strength of conformist biases increased as the number of options increased (i.e. 60% of people wearing black shirts is more persuasive in a world of black, red, blue, yellow, and white shirt colors than in a world of only black shirts and white shirts). These results mean that all prior experiments have underestimated reliance on social learning and the strength of conformist transmission, since all use only 2 options.
IQ predicts both social learning and the strength of the conformist bias. IQ predicts less social learning, but has a U-shaped relationship to the strength of the conformist bias. These results suggest that higher IQ individuals are strategically using social learning (using it less, but with a stronger conformist bias when they choose to use other information).